|
||||
Глава 2. Интерфейсы
В предыдущей главе было показано несколько приемов программирования на C++, позволяющих разрабатывать двоичные компоненты повторного использования, которые со временем могут быть модернизированы. По своему смыслу эти приемы идентичны тем, которые используются моделью СОМ. Незначительные различия между методиками предыдущей главы и теми, которые используются СОМ, в большинстве случаев заключаются в деталях и почти всегда достаточно обоснованы. Вообще-то предыдущая глава прослеживала историю модели СОМ, которая прежде всего и в основном есть отделение интерфейса от реализации. Снова об интерфейсах и реализациях Снова об интерфейсах и реализацияхЦель отделения интерфейса от реализации заключалась в сокрытии от клиента всех деталей внутренней работы объекта. Этот фундаментальный принцип предусматривал уровень косвенности, или изоляции (level of indirection), который позволял изменяться количеству или порядку элементов данных в реализации класса без перекомпиляции клиента. Кроме того, этот принцип позволял клиентам обнаруживать расширенную функциональность путем опроса объекта на этапе выполнения. И, наконец, этот принцип позволяет сделать библиотеку DLL независимой от транслятора C++, который используется клиентом. Хотя этот последний аспект и полезен, он далеко не достаточен для обеспечения универсальной основы для двоичных компонентов. Важно отметить, что хотя клиенты могут использовать любой выбранный ими транслятор C++, в конечном счете это будет всего лишь транслятор C++. Приемы, описанные в предыдущей главе, обеспечивают независимость от транслятора. В конце концов, главное, что необходимо для создания действительно универсальной основы для двоичных компонентов, – это независимость от языка. А чтобы достичь независимости от языка, принцип отделения интерфейса от реализации должен быть применен еще раз. Рассмотрим определения интерфейса, использованные в предыдущей главе. Каждое определение интерфейса принимало форму определения абстрактного базового класса C++ в заголовочном файле C++. Тот факт, что определение интерфейса постоянно находится в файле, читаемом только на одном языке, вскрывает один остаточный признак реализации этого объекта – язык, на котором он был написан. Но, в конечном счете, объект должен быть доступен для любого языка, а не только для того, который выбрал разработчик объекта. Предусматривая только совместимое с C++ определение интерфейса, разработчик объекта тем самым вынуждает всех использующих этот объект также работать на C++. Хотя C++ – чрезвычайно полезный язык программирования, существует множество областей программирования, где больше подходят другие языки. Но точно так же, как проблемы совместимости при компоновке можно решить путем обеспечения всех существующих компиляторов файлами определения модуля, возможно и перевести определение интерфейса с C++ на любые другие языки программирования. А так как двоичная сигнатура интерфейса есть просто сочетание vptr/vtbl, этот перевод может быть сделан для большой группы языков. Проделывание этих языковых преобразований данных для всех известных интерфейсов потребовало бы огромного количества работы, а главное – невозможно успевать делать это для бурного потока языков программирования, которые индустрия программного обеспечения не устает изобретать чуть ли не каждую декаду. Идеально было бы написать сервисную программу, которая переводила бы определения класса C++ в некую абстрактную промежуточную форму. Из этой промежуточной формы такая программа могла бы преобразовывать данные для любого языка программирования, имеющего соответствующий выходной генератор (back-end generator). По мере того как новые языки приобретают значимость, могли бы добавляться новые выходные генераторы, и все ранее определенные интерфейсы смогли бы тотчас использоваться в совершенно новом контексте. К сожалению, язык программирования C++ полон неоднозначностей, что делает его малопригодным для преобразования данных на все мыслимые языки. Многие из этих неоднозначностей приводят к неопределенным соотношениям между указателями, памятью и массивами. Это не является проблемой, когда оба объекта: вызывающий (caller) и вызываемый (callee) – скомпилированы на С или на C++, но они не могут быть точно переведены на другие языки без дополнительной квалификации. Поэтому, чтобы устранить зависимость определения интерфейса от языка, используемого в какой-либо конкретной реализации, необходимо для определений интерфейсов использовать один язык, а для определений реализации – другой. Если все участники договорятся о едином языке для определений интерфейсов, то станет возможным определить интерфейс однажды и получать по мере необходимости новые представления реализации на специфических языках. СОМ предусматривает язык, который основан на хорошо известном синтаксисе С, но добавляет возможность при переводе на другие языки корректно устранить неоднозначность любых особенностей языка С. Этот язык называется языком описаний интерфейса (Interface Definition Language – IDL). IDLСОМ IDL базируется на языке определения интерфейсов основного открытого математического обеспечения удаленного вызова процедур в распределенной вычислительной среде – Open Software Foundation Distributed Computing Environment Remote Procedure Call (OSF DCE RPC). DCE IDL позволяет описывать удаленные вызовы процедур не зависящим от языка способом. Это дает возможность компилятору IDL генерировать код для работы в сети, который прозрачным образом (transparently), то есть незаметно для пользователя, переносит описанные операции на всевозможные сетевые средства сообщения. СОМ IDL просто добавляет некоторые расширения, специфические для СОМ, в DCE IDL для поддержки объектно-ориентированных понятий СОМ (например, наследование, полиморфизм). Не случайно, что когда обращение к объектам СОМ осуществляется через границу контекста выполнения[1] или через границы между машинами, все связи клиент-объект используют MS-RPC (реализация DCE RPC, являющаяся частью Windows NT и Windows 95) как основное средство сообщения. Win32 SDK включает в себя компилятор МIDL.ЕХЕ , который анализирует файлы СОМ IDL и генерирует несколько искусственных объектов – артефактов (artifacts). Как показано на рис. 2.1, MIDL генерирует совместимые с C/C++ заголовочные файлы, которые содержат определения абстрактного базового класса, соответствующие интерфейсам, описанным в исходном IDL-файле. 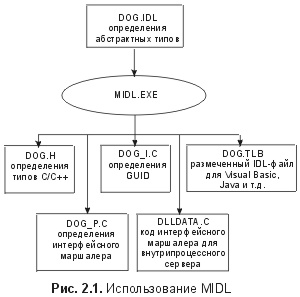 Эти заголовочные файлы также содержат совместимые с С, основанные на структурах определения (structure-based definitions), которые позволяют С-программам обращаться к интерфейсам, описанным на IDL, или обеспечивать их выполнение. То, что MIDL автоматически генерирует С/С++-заголовочный файл, означает, что ни один из СОМ-интерфейсов не нужно определять на C++ вручную. Исход определений из одной точки исключает возникновение множества несовместимых версий определений интерфейсов, которые со временем могут вызвать асинхронность. MIDL также генерирует исходный код, который позволяет использовать интерфейсы в различных потоках, процессах и машинах. Этот код будет обсуждаться в главе 5. И наконец, MIDL может генерировать двоичный файл, который позволяет другим средам, принимающим СОМ, отображать интерфейсы, определенные в исходном IDL-файле, на другие языки. Этот двоичный файл называется библиотекой типа (type library) и содержит разобранный файл IDL в наиболее эффективной для анализа форме. Библиотеки типа обычно распространяются как часть исполняемого файла реализации и позволяют таким языкам, как Visual Basic, Java, Object Pascal использовать интерфейсы, которые выставляются этой реализацией. Чтобы понять IDL, необходимо рассмотреть логический и физический аспекты интерфейса. Обсуждение методов интерфейса и выполняемых ими операций относятся к логическому аспекту интерфейса. Обсуждение памяти, стекового фрейма, сетевых пакетов и других динамических явлений обычно относятся к физическому аспекту интерфейса. Некоторые физические аспекты интерфейса могут непосредственно наследовать логическому описанию (например, расположение таблицы vtbl , порядок параметров в стеке). Другие физические аспекты (например, границы массивов, сетевые представления сложных типов данных) требуют дополнительной квалификации. IDL позволяет разработчикам интерфейса работать непосредственно в сфере логики, используя синтаксис С. Но в то же время IDL требует от разработчиков точно определять все те аспекты интерфейса, которые не могут быть воспроизведены непосредственно по их логическому описанию на С, с помощью использования аннотаций, формально называемых атрибутами. Атрибуты IDL легко распознать в основном тексте IDL: разделенные запятыми, они заключены в скобки. Атрибуты всегда предшествуют описанию объекта, к которому они относятся. Например, в следующем IDL– фрагменте [ v1enum, helpstring(«This is a color!») ] enum COLOR { RED, GREEN, BLUE }; атрибут v1_enum относится к описанию перечисления (enumeration) COLOR. Этот атрибут информирует компилятор IDL о том, что представление COLOR при передаче значения через сеть должно иметь 32 бита, а не 16, как принято по умолчанию. Атрибут helpstring также относится к СОLОR и добавляет строку «This is a color!» («Это – цвет!») в создаваемую библиотеку типа как описание этого перечисления. Если игнорировать атрибуты в IDL-файле, то его синтаксис такой же, как в С. IDL поддерживает структуры, объединения, массивы, перечисления, а также определения типа (typedef) – с синтаксисом, идентичным их аналогам в С. Определяя методы СОМ в IDL, необходимо четко указать, кто – вызывающий или вызываемый объект – будет записывать или читать каждый параметр метода. Это выполняется с помощью атрибутов параметра [in] и [out]: void Method1([in] long arg1, [out] long *parg2, [in, out] long *parg3); Для этого фрагмента IDL предполагается, что вызывающий объект передаст значение в объект arg1 и по адресу, содержащемуся в указателе parg3. По завершении возвращаемые значения будут получены вызывающим объектом по адресам, указанным в parg2 и parg3. Это означает, что для последовательности вызовов: long arg2 = 20, arg3 = 30; p->Method1(10, &arg2, &arg3); объект не может полагаться на получение передаваемого значения 20 через parg2. Если объект запускается в том же контексте выполнения, что и вызывающий объект, и оба участника вызова реализованы на C++, то *parg2 действительно будет иметь на входе метода значение 20. Однако если объект вызывается из другого контекста выполнения или один из участников вызова реализован на языке, который сводит на нет оптимизацию начальных значений чисто выходных (out-only) параметров, то инициализация параметра вызывающим объектом будет утеряна. Методы и их результатыРезультаты методов – это одна из сторон СОМ, где логический и физический миры расходятся. В сущности, все методы СОМ физически возвращают номер ошибки с типом НRESULT. Использование одного типа возвращаемого результата позволяет удаленной COM-архитектуре перегружать результат выполнения метода, а также сообщать об ошибках соединения, просто зарезервировав ряд величин для RPC-ошибок. Величины НRESULT представляют собой 32-битные целые числа, которые передают в вызывающий контекст выполнения информацию о типе ошибок, которые могут произойти (например, ошибки сети, сбои сервера). Во многих языках, поддерживающих СОМ (например, Visual Basic, Java), HRESULT–значения перехватываются контекстом выполнения или виртуальной машиной и преобразуются в программные исключения (programmatic exceptions). 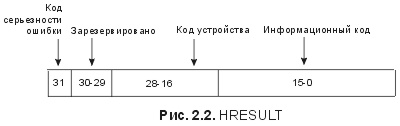 Как показано на рис. 2.2, HRESULT-значения состоят из трех битовых полей: бита серьезности ошибки (severity bit), кода устройства и информационного кода. Бит серьезности ошибки показывает, успешно выполнена операция или нет, код устройства индицирует, к какой технологии относится HRESULT , а информационный код представляет собой точный результат в рамках заданной технологии и серьезности. Заголовки SDK (software development kit – набор инструментальных средств разработки программного обеспечения) определяют два макроса, облегчающие работу с HRESULT: #define SUCCEEDED(hr) (long(hr) >= 0) #def1ne FAILED(hr) (long(hr) < 0) Эти два макроса используют тот факт, что при трактовке НRESULT как целого числа со знаком бит серьезности ошибки он является также знаковым битом. Заголовки SDK содержат определения всех стандартных HRESULT. Эти HRESULT имеют символические имена, соответствующие трем компонентам HRESULT, и используются в следующем формате: <facility>_<severity>_<information> Например, HRESULT с именем STG_S_CONVERTED показывает, что кодом устройства является FACILITY_STORAGE. Это означает, что результат относится к структурированному хранилищу (Structured Storage) или к персистентности (Persistence). Код серьезности ошибки – SEVERITY_SUCCESS. Это означает, что вызов смог успешно выполнить операцию. Третья составляющая – CONVERTED – означает, что в данном случае было произведено преобразование базового файла для поддержки структурированного хранилища. HRESULT-значения, являющиеся универсальными и не привязанными к определенной технологии, используют FACILITY_NULL, и их символическое имя не содержит префикса кода устройства. Вот некоторые стандартные имена HRESULT-значений с кодом FACILITY_NULL: S_OK – успешная нормальная операция S_FALSE – используется для возвращения логического false в случае успеха E_FAIL – общий сбой E_NOTIMPL – метод не реализован E_UNEXPECTED – метод вызван в неподходящее время FACILITY_ITF используется в специфически интерфейсных HRESULT-значениях и является в то же время единственным допустимым кодом устройства для HRESULT, определяемых пользователем. При этом значения FACILITY_ITF должны быть уникальными в контексте каждого отдельного интерфейса. Стандартные заголовки определяют макрос MAKE_HRESULT для определения пользовательского HRESULT из трех необходимых полей: const HRESULT CALC_E_IAMHOSED = MAKE_HRESULT(SEVERITY_ERROR, FACILITY_ITF, 0х200 + 15); Для пользовательских HRESULT принято соглашение, что значения информационного кода должны превышать 0х200 , чтобы избежать повторного использования значений, уже задействованных в системных HRESULT -значениях. Хотя это не опасно, таким образом предотвращается повторное использование значений, уже имеющих смысл для стандартных интерфейсов. Например, большинство HRESULT имеют текстовые описания для пользователя, которые можно получить на этапе выполнения с помощью функции API FormatMessage. Выбор HRESULT, не пересекающихся со значениями, определенными в системе, служит гарантией того, что неверные сообщения об ошибках не будут получены. Чтобы позволить методам возвращать логический результат, не имеющий отношения к их физическому HRESULT -значению, язык СОМ IDL поддерживает атрибут параметров retval . Атрибут retval показывает, что соответствующий параметр физического метода в действительности является логическим результатом операции и, если контекст это позволяет, должен быть представлен как результат операции. Рассмотрим IDL-описание следующего метода: HRESULT Method2([in] short arg1, [out, retval] short *parg2); на языке Java это соответствует: public short Method2(short arg1); в то время как Visual Basic дает такое описание метода: Function Method2(arg1 as Integer) As Integer Поскольку C++ не использует поддержку контекста выполнения для обращения к СОМ-интерфейсам, представление этого метода в Microsoft C++ имеет вид: virtual HRESULT stdcall Method2(short arg1, short *parg2) = 0; Это значит, что следующий клиентский код на языке C++: short sum = 10; short s; HRESULT hr = pItf->Method2(20, &s); if (FAILED(hr)) throw hr; sum += s; примерно эквивалентен такому Java-коду: short sum == 10; short s = Itf.Method2(20); sum += s; Если HRESULT, возвращенный методом, сообщает об аварийном результате, то Java Virtual Machine преобразует HRESULT в исключение Java. Во фрагменте кода на языке C++ необходимо проверить вручную HRESULT, возвращенный этим методом, и соответствующим образом обработать этот аварийный результат. Интерфейсы и IDLОпределения методов в IDL являются просто аннотированными аналогами С-функций. Определения интерфейсов в IDL требуют расширения по сравнению с С, так как С не имеет встроенной поддержки этого понятия. Определение интерфейса в IDL начинается с ключевого слова interface. Это определение состоит их четырех частей: имя интерфейса, базовое имя интерфейса, тело интерфейса и атрибуты интерфейса. Тело интерфейса представляет собой просто набор определений методов и операторов определения типов: [ attribute1, attribute2, …] interface IThisInterface : IBaseInterface { typedef1; typedef2; : : method1; method2; } Каждый интерфейс СОМ должен иметь как минимум два атрибута IDL. Атрибут [object] служит признаком того, что данный интерфейс является СОМ-, а не DCE-интерфейсом. Второй обязательный атрибут указывает на физическое имя интерфейса (в предшествующем IDL-фрагменте IThisInterface является логическим именем интерфейса). Чтобы понять, почему СОМ-интерфейсы требуют физическое имя, отличное от логического имени интерфейса, рассмотрим следующую ситуацию. Два разработчика независимо друг от друга решили создать интерфейс, моделирующий ручной калькулятор. Два их определения интерфейса будут, вероятно, похожими, будучи заданными в общей проблемной области, но скорее всего фактический порядок определений методов и, возможно, сигнатур методов могут в чем-то различаться. Несмотря на это, оба разработчика, вероятно, выберут одно и то же логическое имя: ICalculator. Клиентская программа на машине какого-нибудь конечного пользователя может реализовать определение интерфейса от первого разработчика, а запустить объект, созданный вторым. Поскольку оба интерфейса имеют одно и то же логическое имя, то если клиент запросит объект для поддержки ICalculator, просто использовав строку «ICalculator», объект ответит на запрос возвратом ненулевого указателя интерфейса. Однако представление клиента о том, на что похож ICalculator, вступит в конфликт с тем, какое представление о нем имеет этот объект, и результирующий указатель будет не тем, которого ожидает клиент. Ведь эти два интерфейса могут быть совершенно разными, несмотря на то, что оба используют одно и то же логическое имя. Чтобы исключить коллизию имен, всем СОМ-интерфейсам на этапе проектирования назначается уникальное двоичное имя, которое является физическим именем интерфейса. Эти физические имена называются глобально уникальными идентификаторами (Globally Unique Identifiers – GUIDs), что рифмуется со словом squids [1]. GUID используются в СОМ повсюду для именования статических сущностей, таких как интерфейсы или реализации. GUID являются чрезвычайно большими 128-битными числами, что гарантирует их уникальность как во времени, так и в пространстве. GUID в СОМ основаны на универсальных уникальных идентификаторах (Universally Unique Identifiers – UUIDs), используемых в DCE RPC. При использовании GUID для именования СОМ-интерфейсов их часто называют идентификаторами интерфейса (Interface IDs – IIDs). Реализации в СОМ также именуются с помощью GUID, и в этом случае GUID называются идентификаторами класса (Class IDs – CLSIDs ). Будучи представленными в текстовой форме, GUID всегда имеют следующий канонический вид: BDA4A270-A1BA-11d0-8C2C-0080C73925BA Эти 32 шестнадцатеричные цифры представляют 128-битное значение GUID. Именование интерфейсов и реализации с помощью GUID важно для предотвращения коллизий между разными компонентами. Для создания нового GUID в СОМ имеется API-функция, которая использует децентрализованный алгоритм уникальности для генерирования нового 128-битного числа, которое никогда больше не встретится в природе: HRESULT CoCreateGuid(GUID *pguid); Алгоритм, задействованный в функции CoCreateGuid, использует локальный сетевой интерфейсный адрес машины, текущее машинное время и два постоянных счетчика для компенсации точности часов и нестандартных изменении в них (таких, как переход на летнее время или ручная коррекция системных часов). Если данная машина не имеет сетевого интерфейса, то синтезируется статистически уникальная величина и CoCreateGuid возвращает особого вида HRESULT, показывающий, что данная величина является глобально уникальной только статистически и может считаться таковой только при использовании на локальной машине. Хотя прямой вызов функции CoCreateGuid иногда полезен, большинство разработчиков вызывают ее в неявной форме, применяя из SDK программу GUIDGEN.EXE. На рис. 2.3 показана работа GUIDGEN. GUIDGEN вызывает CoCreateGuid и преобразует полученный GUID в один из четырех форматов, удобных для включения в исходный код на C++ или IDL. При работе в IDL используется четвертый формат (каноническая текстовая форма). 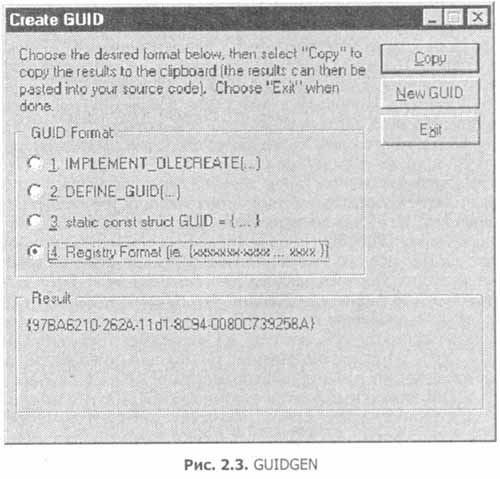 Чтобы связать физическое имя интерфейса с его определением на IDL, используется второй обязательный атрибут интерфейса – [uuid] . Атрибут [uuid] содержит один параметр – каноническую текстовую форму GUID: [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IBaseInterface { HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); } При использовании при программировании на С или C++ физического имени интерфейса IID данного интерфейса представляет собой просто логическое имя интерфейса, предшествуемое префиксом IID_. Например, интерфейс ICalculator будет иметь IID, которым можно программно манипулировать, используя сгенерированную IDL константу IID_ICalculator. Для предотвращения коллизий между символическими именами интерфейсов можно использовать пространство имен C++. Поскольку лишь немногие из компиляторов C++ могут поддерживать 128-битные числа, СОМ определяет С-структуру для представления 128-битовой величины GUID и предлагает псевдонимы для типов IID и CLSID с использованием следующего определения типов: typedef struct GUID { DWORD Data1; WORD Data2; WORD Data3; BYTE Data4[8]; } GUID; typedef GUID IID; typedef GUID CLSID; Внутренняя структура GUID для большинства программистов несущественна, так как единственная значимая операция, которую можно выполнить с GUID, – это проверка их эквивалентности. Для обеспечения эффективной передачи величин GUID как аргументов функций СОМ предусматривает также постоянные псевдонимы для ссылок (constant reference aliases) для каждого типа GUID: #define REFGUID const GUID& #define REFIID const IID& #define REFCLSID const CLSID& Чтобы иметь возможность сравнивать величины GUID, СОМ обеспечивает функции эквивалентности и перегружает операторы == и != для постоянных ссылок GUID: inline BOOL IsEqualGUID(REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); } #def1ne IsEqualIID(r1, r2) IsEqualGUID((r1) , (r2)) #define IsEqualCLSID(r1, r2) IsEqualGUID((r1), (r2)) inline BOOL operator == (REFGUID r1, REFGUID r2) { return !memcmp(&r1, &r2, sizeof(GUID)); } inline BOOL operator != (REFGUID r1, REFGUID r2) { return !(r1 == r2); } Фактические заголовки SDK содержат условно компилируемые совместимые с С версии определений типа, макросов и встраиваемых функций, как показано выше. Поскольку показано, что представления имен интерфейсов на этапе выполнения являются GUID, а не строками; это означает, что метод Dynamic_Cast, описанный в предыдущей главе, следует пересмотреть. Действительно, весь интерфейс IЕхtensibleObject должен быть изменен и преобразован в свой аналог IUnknown, совместимый с СОМ. Интерфейс IUnknownСОМ-интерфейс IUnknown имеет то же назначение, что и интерфейс IExtensibleObject, определенный в предыдущей главе. Последняя версия IExtensibleObject, появившаяся в конце предыдущей главы, имеет вид: class IExtensibleObject { public: virtual void *Dynamic_Cast(const char* pszType) = 0; virtual void DuplicatePointer(void) = 0; virtual void DestroyPointer(void) = 0; } Для определения типа на этапе выполнения был применен метод Dynamic_Cast, аналогичный оператору C++ dynamic_cast. Для извещения объекта о том, что указатель интерфейса дублировался, использовался метод DuplicatePointer. Для сообщения объекту, что указатель интерфейса уничтожен и все используемые им ресурсы могут быть освобождены, был применен метод DestroyPointer. Вот как выглядит определение IUnknown на C++: extern "С" const IID IID_IUnknown: interface IUnknown { virtual HRESULT STDMETHODCALLTYPE QueryInterface(REFIID riid, void **ppv) = 0; virtual ULONG STDMETHODCALLTYPE AddRef(void) = 0; virtual ULONG STDMETHODCALLTYPE Release(void) = 0; }; Заголовочные файлы SDK дают псевдоним interface ключевому слову C++ struct, используя препроцессор С. Поскольку интерфейсы в СОМ определены не как классы, а как структуры, то для того, чтобы сделать методы интерфейса общедоступными, ключевое слово public не требуется. Чтобы создать для целевой платформы СОМ-совместимые стековые фреймы, необходим макрос STDMETHODCALLTYPE. Если целевыми являются платформы Win32, то при использовании компилятора Microsoft C++ этот макрос раскрывается в _stdcall. IUnknown функционально эквивалентен IExtensibleObject. Метод QueryInterface используется для динамического определения типа и аналогичен С++-оператору dynamic_cast. Метод AddRef используется для сообщения объекту, что указатель интерфейса дублирован. Метод Release используется для сообщения объекту, что указатель интерфейса уничтожен и все ресурсы, которые объект поддерживал от имени клиента, могут быть отключены. Главное различие между IUnknown и интерфейсом, определенным в предыдущей главе, заключается в том, что IUnknown использует идентификаторы GUID, а не строки для идентификации типов интерфейса на этапе выполнения. IDL-определение IUnknown можно найти в файле unknwn.idl из директории SDK, содержащей заголовочные файлы: // unknwn.idl – system IDL file // unknwn.idl – системный файл IDL [ local, object, uuid (00000000-0000-0000-C000-000000000046) ] interface IUnknown { HRESULT QueryInterface([in] REFIID riid, [out] void **ppv); ULONG AddRef(void); ULONG Release(void); } Атрибут local подавляет генерирование сетевого кода для этого интерфейса. Этот атрибут необходим для того, чтобы смягчить требования СОМ о том, что все методы при вызове с удаленных машин должны возвращать HRESULT. Как будет показано в следующих главах, интерфейс IUnknown трактуется особым образом при работе с удаленными объектами. Заметим, что фактические, то есть использующиеся на практике IDL-описания интерфейсов, которые содержатся в заголовках SDK, немного отличаются от определений, данных в этой книге. Фактические определения часто содержат дополнительные атрибуты для оптимизации генерируемого сетевого кода, которые не имеют отношения к нашему обсуждению. В случае сомнений обратитесь за полными определениями к последней версии заголовочных файлов SDK. Интерфейс IUnknown является родительским для всех СОМ-интерфейсов. IUnknown – единственный интерфейс СОМ, который не наследует от другого интерфейса. Любой другой допустимый интерфейс СОМ должен быть прямым потомком IUnknown или какого-нибудь другого допустимого интерфейса СОМ, который, в свою очередь, должен сам наследовать или прямо от IUnknown, или от какого-нибудь другого допустимого интерфейса СОМ. Это означает, что на двоичном уровне все интерфейсы СОМ являются указателями на таблицы vtbl, которые начинаются с трех точек входа: QueryInterface, AddRef и Release. Все специфические для интерфейсов методы будут иметь точки входа в vtbl, которые появляются после этих трех общих точек входа. Чтобы наследовать от интерфейса IDL, нужно или определить базовый интерфейс в том же IDL-файле, или использовать директиву import, чтобы сделать внешнее IDL-определение базового интерфейса явным в данной области действия: // calculator.idl [object, uuid(BDA4A270-A1BA-11dO-8C2C-0080C73925BA)] interface ICalculator : IUnknown { import «unknwn.idl»; // bring in def. of IUnknown // импортируем определение IUnknown HRESULT Clear(void); HRESULT Add([in] long n); HRESULT Sum([out, retval] long *pn); } Оператор import может появляться или внутри определения интерфейса, как показано здесь, или предшествовать описанию интерфейса в глобальной области действия. В любом из этих случаев действия оператора import одинаковы, он может многократно импортировать один IDL-файл без всякого ущерба. Поскольку сгенерированный C/C++ заголовочный файл будет требовать С/С++-версии импортируемого IDL-файла, чтобы обеспечить наследование, оператор import из IDL-файла будет странслирован в команду #include в генерируемом заголовочном С/С++-файле: // calculator.h – generated by MIDL // calculator.h – генерированный MIDL // bring in def. of IUnknown // вводим определения IUnknown #include «unknwn.h» extern "C" const IID IID_ICalculator; interface ICalculator : public IUnknown { virtual HRESULT STDMETHODCALLTYPE Clear(void) = 0; virtual HRESULT STDMETHODCALLTYPE Add(long n) = 0; virtual HRESULT STDMETHODCALLTYPE Sum(long *pn) = 0; } Компилятор MIDL также создаст С-файл, содержащий фактические определения всех GUID, имеющихся в исходном IDL-файле: // calculator_i.с – generated by MIDL const IID IID_ICalculator = { 0xBDA4A270, 0xA1BA, 0x11d0, { 0x8C, 0x2C, 0x00, 0х80, 0хC7, 0х39, 0x25, 0xBA } }; Каждый проект, который будет использовать этот интерфейс, должен или добавить calculator_i.c к своему файлу сборки (makefile), или включить calculator_i.c в один из исходных файлов на С или C++ с использованием препроцессора С. Если это не сделано, то идентификатору IID_ICalculator не будет выделено памяти для его 128-битного значения и проект не будет скомпонован по причине неразрешенных внешних идентификаторов. СОМ не накладывает никаких ограничений на глубину иерархии интерфейсов при условии, что конечным базовым интерфейсом является IUnknown. Нижеследующий IDL является вполне допустимым и корректным для СОМ: import «unknwn.idl»; [object, uuid(DF12E151-A29A-11d0-8C2D-0080C73925BA)] interface IAnimal : IUnknown { HRESULT Eat(void); } [object, uuid(DF12E152-A29A-11d0-8C2D-0080C73925BA)] interface ICat : IAnimal { HRESULT IgnoreMaster(void); } [object, uuid(DF12E153-A29A-11d0-8C2D-0080C73925BA)] interface IDog : IAnimal { HRESULT Bark(void); } [object, uuid(DF12E154-A29A-11d0-8C2D-0080C73925BA)] interface IPug : IDog { HRESULT Snore(void); } [object, uuid(DF12E155-A29A-11d0-8C2D-0080C73925BA)] interface IOldPug : IPug { HRESULT SnoreLoudly(void); } СОМ накладывает одно ограничение на наследование интерфейсов: интерфейсы СОМ не могут быть прямыми потомками более чем одного интерфейса. Следующий фрагмент в СОМ недопустим: [object, uuid(DF12E156-A29A-11d0-8C2D-0080C73925BA)] interface ICatDog : ICat, IDog { // illegal, multiple bases // неверно, несколько базовых интерфейсов HRESULT Meowbark(void); } СОМ запрещает наследование от нескольких интерфейсов по целому ряду причин. Одна из них состоит в том, что двоичное представление результирующего абстрактного базового класса C++ не будет независимым от компилятора. В этом случае СОМ уже не будет являться двоичным стандартом, независимым от разработчика. Другая причина кроется в тесной связи между СОМ и DCE RPC. При ограничении наследования интерфейсов одним базовым интерфейсом преобразование между интерфейсами СОМ и интерфейсными векторами DCE RPC вполне однозначно. В конце концов, отсутствие поддержки нескольких базовых интерфейсов не является ограничением, так как каждая реализация может выбрать для открытия столько интерфейсов, сколько пожелает. Это означает, что основанный на СОМ Cat/Dog по-прежнему допустим на уровне реализации: class CatDog : public ICat, public IDog { // ... }; Клиент, желающий трактовать объект как Cat/Dog, просто использует QueryInterface для привязки к объекту обоих типов указателей. Если один из вызовов QueryInterface не достигает успеха, то данный объект не является Cat/Dog и клиент может справляться с этим, как сумеет. Поскольку реализации могут открывать несколько интерфейсов, то запрет для интерфейсов наследовать более чем от одного интерфейса является лишь небольшой потерей в смысле семантической информации или информации о типе. СОМ поддерживает стандарт обозначений, который показывает, какие интерфейсы доступны из объекта. Этот способ придерживается философии СОМ относительно отделения интерфейса от реализации и не раскрывает никаких деталей реализации объекта иначе, чем через список выставляемых им интерфейсов. 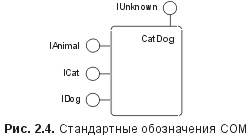 Рисунок 2.4 показывает стандартное обозначение класса CatDog. Заметим, что из этой схемы можно сделать единственный вывод: если не произойдет катастрофических сбоев, объекты CatDog выставят четыре интерфейса: ICat, IDog, IAnimal и IUnknown. Управление ресурсами и IUnknownКак было в случае с DuplicatePointer и DestroyPointer из предыдущей главы, методы AddRef и Release из IUnknown имеют очень простой протокол, которого должны придерживаться все, кто пользуется указателями этих интерфейсов. Эти правила освобождают клиента от необходимости управлять временем жизни объекта, когда несколько интерфейсных указателей могут указывать или не указывать на один и тот же объект. Клиентам необходимо только следовать простым правилам AddRef/Release единообразно для всех интерфейсных указателей, с которыми им приходится сталкиваться, а объект будет сам управлять своим временем жизни. Спецификация модели компонентных объектов (Component Object Model Specification) содержит четкие определения правил подсчета ссылок СОМ. Понимание мотивировки этих определений имеет решающее значение при СОМ-программировании на C++. Эти правила СОМ о подсчете ссылок могут быть сведены к трем простым аксиомам: Когда ненулевой указатель интерфейса копируется из одной ячейки памяти в другую, должен вызываться AddRef для извещения объекта о дополнительной ссылке. Перед тем как произойдет перезапись той ячейки памяти, где содержится ненулевой указатель интерфейса, необходимо вызвать Release, чтобы известить объект, что ссылка уничтожается. Избыточное количество вызовов AddRef и Release можно сократить, если иметь дополнительную информацию о связях между двумя и более ячейками памяти. Аксиома о дополнительной информации введена главным образом для того, чтобы ввести возможность преобразования запутанных ситуаций в разумные и осмысленные идиомы программирования (например, стеки временных вызовов и сгенерированное компилятором занесение переменной в регистр не нуждаются в подсчете ссылок). Можно провести месяцы в поиске особых связей между переменными, содержащими явные указатели на интерфейс в программе и оптимизировать избыточные вызовы AddRef и Release , но поступать так было бы неосмотрительно. Выгода от удаления этих избыточных вызовов явно незначительна, так как даже в худшем случае, когда объект вызывается с расстояния более 8500 миль со средней скоростью передачи 14.4 кбит/сек, эти избыточные вызовы никогда не уйдут из вызывающего потока и нечасто требуют множество инструкций для выполнения. Если руководствоваться приведенными выше тремя простыми аксиомами о подсчете ссылок в интерфейсных указателях, то можно записать это в виде руководящих принципов программирования, чтобы установить, когда вызывать и когда не вызывать AddRef и Release . Вот несколько типичных ситуаций, требующих вызова метода AddRef: А1. Когда ненулевой интерфейсный указатель записывается в локальную переменную. А2. Когда вызываемый объект пишет ненулевой интерфейсный указатель в параметр [out] или [in, out] метода или функции. A3. Когда вызываемый объект возвращает ненулевой интерфейсный указатель как физический результат (physical result) функции. А4. Когда ненулевой интерфейсный указатель пишется в элемент данных объекта. Некоторые типичные ситуации, требующие вызова метода Release : R1. Перед перезаписью ненулевой локальной переменной или элемента данных. R2. Перед тем как покинуть область действия ненулевой локальной переменной. R3. Когда вызываемый объект перезаписывает параметр [in,out] метода или функции, начальное значение которых отлично от нуля. Заметим, что параметры [out] предполагаются нулевыми при вводе и никогда не могут освобождаться вызываемым объектом. R4. Перед перезаписью ненулевого элемента данных объекта. R5. Перед завершением работы деструктора объекта, имеющего в качестве элемента данных ненулевой интерфейсный указатель. Типичная ситуация, к которой применимо правило о дополнительной информации, возникает при передаче указателей интерфейсов функциям как параметрам [in]: S1. Когда при вызове функции или метода ненулевой интерфейсный указатель передается через [in] -параметр, вызов AddRef и Release, не требуются, так как время жизни временной переменной в стеке является строгим подмножеством времени жизни выражения, использованного для инициализации формального аргумента. Эти десять руководящих принципов охватывают ситуации, снова и снова возникающие при программировании в СОМ, и было бы неплохо их запомнить. Чтобы конкретизировать правила подсчета ссылок в СОМ, предположим, что имеется глобальная функция, которая возвращает объекту интерфейсный указатель: void GetObject([out] IUnknown **ppUnk); и что имеется другая глобальная функция, которая выполняет некую полезную работу над объектом: void UseObject([in] IUnknown *pUnk); Написанный ниже код использует эти процедуры, чтобы управлять некоторыми объектами и возвращать интерфейсный указатель вызывающему объекту. Руководящие принципы, применимые к каждому оператору, указаны в комментариях к нему: void GetAndUse(/* [out] */ IUnknown ** ppUnkOut) { IUnknown *pUnk1 = 0, *pUnk2 = 0; *ppUnkOut =0; // R3 // get pointers to one (or two) objects // получаем указатели на один (или два) объекта GetObject(&pUnk1); //A2 GetObject(&pUnk2); //A1 // set pUnk2 to point to first object // устанавливаем pUnk2, чтобы указать на первый объект if (pUnk2) pUnk2->Release(): //R1 if (pUnk2 = pUnk1) pUnk2->AddRef(): //A1 // pass pUnk2 to some other function // передаем pUnk2 какой-нибудь другой функции UseObject(pUnk2); //S1 // return pUnk2 to caller using ppUnkOut parameter // возвращаем pUnk2 вызывающему объекту, используя // параметр ppUnkOut if (*ppUnkOut = pUnk2) (*ppUnkOut)->AddRef(); // A2 // falling out of scope so clean up // выходит за область действия и поэтому освобождаем if (pUnk1) pUnkl->Release(); //R2 if (pUnk2) pUnk2->Release(); //R2 } Важно отметить, что в вышеприведенном коде правило A2 применяется дважды, но по двум разным причинам. При вызове GetObject код выступает как вызывающий объект, а реализация GetObject является вызываемым объектом. Это означает, что реализация GetObject является ответственной за вызов AddRef через параметр [out]. При перезаписи памяти, на которую ссылается ppUnkOut, код выступает как вызываемый объект и корректно вызывает AddRef через интерфейсный указатель перед возвратом управления вызывающему объекту. Существуют некоторые тонкости относительно AddRef и Release, подлежащие обсуждению. Как AddRef, так и Release предназначались для возврата 32-битного целого числа без знака. Это целое число отражает общее количество оставшихся ссылок после применения операций AddRef или Release. Однако по целому ряду причин, связанных с многопоточным режимом, удаленным доступом и мультипроцессорной архитектурой, нельзя быть уверенным в том, что эта величина будет точно отражать общее число неосвобожденных интерфейсных указателей, и клиенту следует игнорировать ее, если только она не используется в целях диагностики при отладке. Единственный случай, заслуживающий внимания, это когда Release возвращает нуль. Нулевой результат от Release надежно свидетельствует о том, что данный объект более не действителен ни в каком смысле. Однако обратное неверно. Это значит, что когда Release возвращает не нуль, нельзя утверждать, что объект еще работоспособен. Фактически, если Release был вызван указателем интерфейса столько же раз, сколько этим же указателем интерфейса был вызван AddRef , то данный указатель интерфейса недействителен и более не обеспечивает указание на действующий объект. В то же время возможно, что это – случайность, а объект все еще работоспособен благодаря другим, еще не освобожденным, указателям, и все может измениться в самый неподходящий момент. Чтобы однажды освобожденные (released) интерфейсные указатели более не использовались, можно, например, обнулять их сразу же после вызова метода Release: inline void SafeRelease(IUnknown * &rpUnk) { if (rpUnk) { rpUnk->Release(); rpUnk = 0; // rpUnk passed by reference // rpUnk, переданный ссылкой } } Когда этот способ применен, любое использование указателя интерфейса после его высвобождения немедленно вызовет ошибку доступа. Эта ошибка затем может быть достоверно воспроизведена и, можно надеяться, отловлена еще на этапе разработки. Еще одна тонкость, относящаяся к AddRef и Release, состоит в выходе из блока. Функция GetAndUse , приведенная ранее, имеет только одну точку выхода. Это означает, что операторы, высвобождающие указатели интерфейса в конце функции, будут всегда выполняться ранее завершения работы функции. Если же функция завершит работу, не доходя до этих операторов – либо благодаря явному оператору return или же, что хуже, необработанному (unhandled) исключению C++, – то эти завершающие операторы будут пропущены и все ресурсы, удерживаемые неосвобожденными интерфейсными указателями, будут утеряны до окончания клиентской программы. Это означает, что к указателям интерфейса СОМ следует относиться с осторожностью, особенно при использовании их в средах, использующих исключения C++. Впрочем, это касается и других системных ресурсов, с которыми приходится работать, будь то семафоры или динамически распределяемая память. Далее в этой главе обсуждаются интеллектуальные СОМ-указатели, которые обеспечивают вызов Release во всех ситуациях. Приведение типов и IUnknownВ предыдущей главе обсуждалось, почему необходимо определять тип на этапе выполнения в динамически собранной системе. Язык C++ предусматривает разумный механизм для динамического определения типа с помощью оператора dynamic_cast. Хотя эта языковая возможность имеет собственную реализацию для каждого компилятора, в предыдущей главе было предложено средство урегулирования этого – добавление к каждому интерфейсу явного метода, являющегося семантическим эквивалентом dynamic_cast. Ниже приводится IDL-описание QueryInterface: HRESULT QueryInterface([in] REFIID riid, [out] void **ppv); Первый параметр (riid) является физическим именем запрошенного интерфейса. Второй параметр (ppv) указывает на переменную интерфейсного указателя, которая в случае успешного завершения будет содержать запрошенный указатель на интерфейс. В ответ на запрос QueryInterface, если объект не поддерживает запрошенный тип интерфейса, он должен возвратить E_NOINTERFACE после установки *ppv в нулевое значение. Если же объект поддерживает запрошенный интерфейс, он должен перезаписать *ppv указателем запрошенного типа и возвратить HRESULT S_OK. Поскольку ppv является [out]-параметром, реализация QueryInterface должна выполнить AddRef для возвращаемого указателя перед тем, как вернуть управление вызывающему объекту (см. в этой главе выше руководящий принцип А2). Этот вызов AddRef должен быть согласован с вызовом Release со стороны клиента. Следующий код показывает динамическое определение типа с использованием оператора C++ dynamic_cast на примере иерархии типов Dog/Cat, описанного ранее в данной главе: void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { IPug *pPug = 0; pPug = dynamic_cast<IPug*> (pUnk); if (pPug) // the object is Pug-compatible // объект совместим с Pug pPug->Snore(); ICat *pCat = 0; pCat = dynamic_cast<ICat*>(pUnk); if (pCat) // the object is Cat-compatible // объект совместим с Cat pCat->IgnoreMaster(); } Если объект, переданный этой функции, совместим одновременно с ICat и с IDog, то задействованы обе функциональные возможности. Если же объект в действительности не совместим с ICat или с IDog, то данная функция просто проигнорирует пропущенный аспект объекта (или оба аспекта сразу). Ниже показан семантически эквивалентный вариант с использованием QueryInterface: void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { HRESULT hr; IPug *pPug = 0; hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug); if (SUCCEEDED(hr)) { // the object is Pug-compatible // объект совместим с Pug pPug->Snore(); pPug->Release(); // R2 } ICat *pCat = 0; hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat); if (SUCCEEDED(hr)) { // the object is Cat-compatible // объект совместим с Cat pCat->IgnoreMaster(); pCat->Release(); // R2 } } Хотя имеются очевидные различия в синтаксисе, единственная существенная разница между двумя приведенными фрагментами кода состоит в том, что вариант, основанный на QueryInterface, подчиняется правилам подсчета ссылок СОМ. Есть несколько тонкостей, связанных с QueryInterface и его употреблением. Метод QueryInterface может возвращать указатели только на тот же самый СОМ-объект, для которого он вызван. Глава 4 посвящена объяснению каждого нюанса этого оператора. Полезно, однако, отметить уже сейчас, что клиент не должен трактовать AddRef и Release как операции с объектом. Вместо этого следует рассматривать их как операции с указателем интерфейса. Это означает, что нижеследующий код ошибочен: void BadCOMCode(/*[in]*/ IUnknown *pUnk) { ICat *pCat = 0; IPug *pPug = 0; HRESULT hr; hr = pUnk->QueryInterface(IID_ICat, (void**)&pCat); if (FAILED(hr)) goto cleanup; hr = pUnk->QueryInterface(IID_IPug, (void**)&pPug); if (FAILED(hr)) goto cleanup; pPug->Bark(); pCat->IgnoreMaster(); cleanup: if (pCat) pUnk->Release(); // pCat got AddRefed in QI // pCat получил AddRef в QI if (pPug) pUnk->Release(); // pDog got AddRefed in QI // pDog получил AddRef в QI } Несмотря на то что все три указателя: pCat, pPug и pUnk – указывают на тот же самый объект, клиент не имеет права компенсировать AddRef, который происходит для pCat и pPug при вызове QueryInterface, вызовами Release для pUnk. Правильный вариант этого кода такой: cleanup: if (pCat) pCat->Release(); // use AddRefed ptr // используем указатель AddRef if (pPug) pPug->Release(); // use AddRefed ptr // используем указатель AddRef Здесь Release вызывается для того же интерфейсного указателя, для которого и AddRef (что произошло неявно, когда указатель был возвращен из QueryInterface). Это требование предоставляет разработчику значительную гибкость при реализации объекта. Например, объект может решить подсчитывать ссылки на каждый интерфейс, чтобы активным образом использовать ресурсы, которые обычно используются одним определенным интерфейсом на объект. Еще одна тонкость относится ко второму параметру QueryInterface, имеющему тип void**. Весьма забавно то, что QueryInterface, являющийся основой системы типов СОМ, имеет довольно сомнительный в смысле типа аналог в C++: HRESULT _stdcall QueryInterface(REFIID riid, void** ppv); Как было отмечено ранее, клиенты вызывают QueryInterface, передавая объекту указатель на интерфейсный указатель в качестве второго параметра вместе с IID, который определяет тип ожидаемого интерфейсного указателя: IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)&pPug); К сожалению, для компилятора C++ таким же правильным выглядит и следующее: IPug *pPug = 0; hr = punk->QueryInterface(IID_ICat, (void**)&pPug); Даже еще более хитроумный вариант компилируется без ошибок: IPug *pPug = 0; hr = punk->QueryInterface(IID_IPug, (void**)pPug); Исходя из того, что правила наследования неприменимы к указателям, такое альтернативное определение QueryInterface нe облегчает проблему: HRESULT QueryInterface(REFIID riid, IUnknown** ppv); так как неявное приведение типа к родительскому типу (upcasting) применимо только к объектам и указателям на объекты, а не к указателям на указатели на объекты: IDerived **ppd; IBase **ppb = ppd; // illegal // неверно To же ограничение применимо в равной мере и к ссылкам на указатели. Следующее альтернативное определение вряд ли более удобно для использования клиентами: HRESULT QueryInterface(const IID& riid, void* ppv); так как позволяет клиентам отказаться от приведения типа (cast). К сожалению, это решение не уменьшает количества ошибок (обе из предшествующих ошибок все еще возможны), а устраняя необходимость приведения, уничтожает и видимый индикатор того, что устойчивость типов C++ может оказаться в опасности. Если желательна семантика QueryInterface, то выбор типов аргументов, сделанный корпорацией Microsoft, по крайней мере, разумен, если не надежен или изящен. Простейший путь избежать ошибок, связанных c QueryInterface,– это всегда быть уверенным в том, что IID соответствует типу указателя интерфейса, который проходит как второй параметр QueryInterface. На самом деле первый параметр QueryInterface описывает «форму» типа указателя второго параметра. Их связь может быть усилена на этапе компиляции с помощью такого макроса предпроцессора С: #define IID_PPV_ARG(Type, Expr) IID_##type, reinterpret_cast<void**>(static_cast<Type **>(Expr)) С помощью этого макроса[1] компилятор будет уверен в том, что выражение, использованное в приведенном ниже вызове QueryInterface, имеет правильный тип и что используется соответствующий уровень изоляции (indirecton): IPug *pPug = 0; hr = punk->QueryInterface(IID_PPV_ARG(IPug, &pPug)); Этот макрос закрывает брешь, вызванную параметром void**, без каких-либо затрат на этапе выполнения. Реализация IUnknownИмея описанные выше образцы клиентского использования, легко видеть, как реализовать методы IUnknown. Примем предложенную выше иерархию типов Dog/Cat. Чтобы определить С++-класс, который реализует интерфейсы IPug и ICat , нужно просто добавить к списку базовых классов самые последние в иерархии наследования версии интерфейсов: class PugCat : public IPug, public ICat При использовании наследования компилятор C++ обеспечивает совместимость двоичного представления производного класса с каждым базовым классом. Для класса PugCat это означает, что все объекты PugCat будут содержать указатель vptr, указывающий на таблицу vtbl, совместимую с IPug. Объекты PugCat также будут содержать указатель vptr, указывающий на вторую таблицу vtbl, совместимую с ICat. Рисунок 2.5 показывает, как интерфейсы в качестве базовых классов соотносятся с представлением объектов. Поскольку все функции-члены в СОМ-определениях интерфейса являются чисто виртуальными, производный класс должен обеспечивать реализацию каждого метода, имеющегося в любом из его интерфейсов. Методы, общие для двух или более интерфейсов (например, QueryInterface, AddRef и т. д.) нужно реализовывать только один раз, так как компилятор и компоновщик инициализируют все таблицы vtbl так, чтобы они указывали на одну реализацию метода. Таков естественный побочный эффект от использования множественного наследования в языке C++. 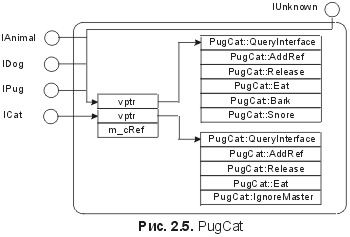 Следующий код является определением класса, которое создает объекты, поддерживающие интерфейсы IPug и ICat: class PugCat : public IPug, public ICat { LONG mcRef; protected: virtual ~PugCat(void); public: PugCat(void); // IUnknown methods // методы IUnknown STDMETHODIMP QueryInterface(REFIID riid, void **ppv); STDMETHODIMP(ULONG) AddRef(void); STDMETHODIMP(ULONG) Release(void); // IAnimal methods // методы IAnimal STDMETHODIMP Eat(void); // IDog methods // методы IDog STDMETHODIMP Bark(void); // IPug methods // методы IPug STDMETHODIMP Snore(void); // ICat methods // методы ICat STDMETHODIMP IgnoreMaster(void); }; Отметим, что в классе должен быть реализован каждый метод, определенный в любом интерфейсе, от которого он наследует, так же, как и каждый метод, определенный в любых производных (implied) базовых интерфейсах (например, IDog, IAnimal ). Для создания стековых фреймов, совместимых с СОМ, необходимо использовать макросы STDMETHODIMP и STDMETHODIMP. При ориентации на платформы Win32, использующие компилятор Microsoft C++, заголовки SDK определяют эти два макроса следующим образом: #define STDMETHODIMP HRESULT stdcall #define STDMETHODIMP(type) type stdcall Заголовочные файлы SDK также определяют макросы STDMETHOD и STDMETHOD , которые можно использовать при определении интерфейсов без IDL-компилятора. В серийно выпускаемом программировании на СОМ эти два макроса не нужны. Реализация AddRef и Release чрезвычайно прозрачна. Элемент данных mcRef отслеживает, сколько неосвобожденных интерфейсных указателей удерживают объект. Конструктор класса приводит счетчик ссылок в нулевое состояние: PugCat::PugCat(void) : mcRef(0) // initialize reference count to zero // устанавливаем счетчик ссылок в нуль { } Реализация AddRef в классе фиксирует путем увеличения счетчика ссылок, что вызывающий объект продублировал указатель интерфейса. Измененное значение счетчика ссылок возвращается для целей диагностики: STDMETHODIMP(ULONG) AddRef(void) { return ++mcRef; } Реализация Release фиксирует уничтожение указателя интерфейса простым уменьшением счетчика ссылок, а также производит соответствующее действие, когда счетчик ссылок достигает нуля. Для объектов, находящихся в динамически распределяемой области памяти, это означает вызов оператора delete для уничтожения объекта: STDMETHODIMP(ULONG) Release(void) { LONG res = -mcRef; if (res == 0) delete this; return res; } Для кэширования обновленного счетчика ссылок необходимо использовать временную переменную, так как нельзя обращаться к элементам данных объекта после того, как объект уже уничтожен. Заметим, что показанные реализации Addref и Release используют собственные операторы инкремента и декремента (увеличения и уменьшения на единицу). Для простой реализации это весьма разумно, так как СОМ не допускает более одного потока для обращения к объекту до тех пор, пока конструктор не обеспечит явный многопоточный доступ (почему и как конструктор сделает это, подробно описано в главе 5). В случае объектов, доступных в многопоточной среде, для автоматического подсчета ссылок следует использовать подпрограммы Win32 InterlockedIncrement/InterlockedDecrement: STDMETHODIMP(ULONG) AddRef(void) { return InterlockedIncrement(&mcRef); } STDMETHODIMP(ULONG) Release(void) { LONG res = InterlockedDecrement(&mcRef); if (res == 0) delete this; return res; } Этот код несколько менее эффективен, чем версии, использующие собственные операторы C++. Но, вообще говоря, разумнее использовать менее эффективные варианты InterlockedIncrement / InterlockedDecrement, так как известно, что они надежны во всех ситуациях и освобождают разработчика от необходимости сохранять две версии практически одинакового кода. Показанные выше реализации AddRef и Release предполагают, что объект может размещаться только в динамически распределяемой области памяти (в «куче») с использованием С++-оператора new. В определении класса деструктор сделан защищенной операцией для обеспечения того, чтобы ни один экземпляр класса не был определен никаким другим способом. Однако иногда желательно иметь объекты, не размещенные в «куче». Для этих объектов вызов delete в последнем вызове Release был бы гибельным. Так как единственной причиной для того, чтобы объект в первую очередь поддерживал счетчик ссылок, была необходимость вызова delete this, допустимо оптимизировать счетчик ссылок для объектов, не содержащихся в динамически распределяемой области памяти: STDMETHODIMP(ULONG) GlobalVar::AddRef(void) { return 2; // any non-zero value is legal // допустима любая ненулевая величина } STDMETHODIMP(ULONG) GlobalVar::Release (void) { return 1; // any non-zero value is legal // допустима любая ненулевая величина } Эта реализация использует тот факт, что результаты AddRef и Release служат только для сведения и не обязаны быть точными. При наличии реализации AddRef и Release единственным еще не реализованным методом из IUnknown остается QueryInterface. Его реализации должны отслеживать иерархию типов объекта и использовать статические приведения типов для возврата правильного типа указателя для всех поддерживаемых интерфейсов. Для определения класса PugCat, рассмотренного ранее, следующий код является корректной реализацией QueryInterface : STDMETHODIMP PugCat::QueryInterface(REFIID riid, void **ppv) { assert(ppv != 0); // or return EPOINTER in production // или возвращаем EPOINTER в реальный продукт if (riid == IIDIPug) *ppv = staticcast<IPug*>(this); else if (riid == IIDIDog) *ppv = staticcast<IDog*>(this); else if (riid == IIDIAnimal) // cat or pug? // кот или мопс? *ppv == staticcast<IDog*>(this); else if (riid == IIDIUnknown) // cat or pug? // кот или мопс? *ppv = staticcast<IDog*>(this); else if (riid == IIDICat) *ppv = staticcast<ICat*>(this); else { // unsupported interface // неподдерживаемый интерфейс *ppv = 0; return ENOINTERFACE; } // if we reach this point, *ppv is non-null // and must be AddRef'ed (guideline A2) // если мы дошли до этого места, то *ppv ненулевой // и должен быть обработан AddRef'ом ( принцип A2) reinterpretcast<IUnknown*>(*ppv)->AddRef(); return SOK; } Использование staticcast более предпочтительно, чем традиционные приведения типа в стиле С: *ppv = (IPug*)this; так как вариант staticcast вызовет ошибку этапа компиляции, если произведенное приведение типа не согласуется с существующим базовым классом. Заметим, что в показанной здесь реализации QueryInterface при запросе на интерфейс, поддерживающийся более чем одним базовым интерфейсом (например, IUnknown, IAnimal) приведение типа должно явно выбрать более определенный базовый класс. Например, для класса PugCat такой вполне безобидно выглядящий код не откомпилируется: if (riid == IIDIUnknown) *ppv = staticcast<IUnknown*>(this); Этот код не пройдет компиляцию, поскольку такое приведение типа является неоднозначным и может соответствовать более чем одному базовому классу. Это было показано в случае FastString и IExtensibleObject из предыдущей главы. Вместо этого реализация должна более точно выбрать тип для приведения: if (riid == IIDIUnknown) ppv = staticcast<IDog*>(this); или if (riid == IIDIUnknown) ppv = staticcast<ICat*>(this); Каждый из этих двух фрагментов кода допустим для реализации PugCat. Первый вариант предпочтительнее, так как многие компиляторы выдают несколько более эффективный код, когда использован крайний левый базовый класс[1]. Использование указателей интерфейса СОМПрограммисты C++ должны использовать методы IUnknown явно, потому что перевод модели СОМ на язык C++ не предусматривает использования среды поддержки выполнения (runtime layer) между кодом клиента и кодом объекта. Поэтому IUnknown можно рассматривать просто как набор обещаний, которые все программисты СОМ дают друг другу. Это дает преимущество программистам C++, так как C++ может создавать код, который потенциально более эффективен, чем языки, которые требуют такого динамического слоя при работе с СОМ. При работе на Visual Basic и Java, в отличие от C++, программисты никогда не видят QueryInterface, AddRef или Release. Для этих двух языков детали IUnknown надежно скрыты за поддерживающей эти языки виртуальной машиной. На Java QueryInterface просто отображается в приведение типа: public void TryToSnoreAndIgnore(Object obj) { IPug pug; try { pug = (IPug)obj; // VM calls QueryInterface // VM вызывает QueryInterface pug.Snore(); } catch (Throwable ex) { // ignore method or QI failures // игнорируем сбой метода или QI } ICat cat; try { cat = (ICat)obj; // VM calls QueryInterface // VM вызывает QueryInterface cat.IgnoreMaster(); } catch (Throwable ex) { // ignore method or QI failures // игнорируется сбой метода или QI } } Visual Basic не требует от клиентов приведения типов. Вместо этого, когда указатель интерфейса присваивается переменной неподходящего типа, виртуальная машина (VM) Visual Basic молча вызывает QueryInterface от имени клиента: Sub TryToSnoreAndIgnore(obj as Object) On Error Resume Next ' ignore errors ' игнорируем ошибки Dim pug as IPug Set pug = obj ' VM calls QueryInterface ' VM вызывает QueryInterface If Not (pug is Nothing) Then pug.Snore End if Dim cat as ICat Set cat = obj ' VM calls QueryInterface ' VM вызывает QueryInterface If Not (cat is Nothing) Then cat.IgnoreMaster End if End Sub Обе виртуальные машины, как Java, так и Visual Basic, выбросят при сбое QueryInterface исключения. В обеих средах виртуальная машина автоматически преобразует языковую концепцию живучести переменной в явные вызовы AddRef и Release , избавляя клиента и от этой подробности. Одна методика, потенциально способная упростить использование в СОМ интерфейсных указателей из C++, состоит в том, чтобы скрыть их в классе интеллектуальных указателей. Это устраняет необходимость необработанных (raw ) вызовов методов IUnknown. В идеале интеллектуальный указатель СОМ будет: Корректно обрабатывать каждый вызов Add/Release во время присваивания. Автоматически уничтожать интерфейс в деструкторе, что снижает возможность утечки ресурса и повышает безопасность (надежность) исключений. Использует систему типов C++ для упрощения вызовов QueryInterface. Прозрачным образом (незаметно для пользователя или программы) замещает необработанные интерфейсные указатели в существующем коде без компрометации правильности программы. Последний пункт представляет собой чрезвычайно серьезную проблему. Интернет забит интеллектуальными СОМ-указателями, которые проделывают прозрачную замену обычных указателей, но при этом вводят столько же скрытых ошибок, сколько претендуют устранить. Visual C++ 5.0, например, фактически действует с тремя такими указателями (один на MSC, другой на ATL, а третий для поддержки Direct-to-COM), которые очень просто использовать как правильно, так и неправильно. В сентябрьском 1995 года и в февральском 1996 года выпусках "C++ Report " опубликованы две статьи, где на примерах показаны различные подводные камни при использовании интеллектуальных указателей[1]. Исходный код, который приводится в данной книге, содержит интеллектуальный СОМ-указатель, созданный в процессе написания этих двух статей. В нем делается попытка учесть общие ошибки, случающиеся как в простых, так и в интеллектуальных указателях СОМ. Класс интеллектуальных указателей, SmartInterface , имеет два шаблонных (template) параметра: тип интерфейса в C++ и указатель на соответствующий IID . Все обращения к методам IUnknown скрыты путем перегрузки операторов: #include «smartif.h» void TryToSnoreAndIgnore(/* [in] */ IUnknown *pUnk) { // copy constructor calls QueryInterface // конструктор копирования вызывает QueryInterface SmartInterface<IPug, &IIDIPug> pPug = pUnk; if (pPug) // typecast operator returns null-ness // оператор приведения типа возвращает нуль pPug->Snore(); // operator-> returns safe raw ptr // оператор -> возвращает прямой указатель // copy constructor calls QueryInterface // конструктор копирования вызывает QueryInterface SmartInterface<ICat, &IIDICat> pCat = pUnk; if (pCat) // typecast operator returns null-ness // оператор приведения типа возвращает нуль pCat->IgnoreMaster(); // operator-> returns safe raw ptr // оператор -> возвращает прямой указатель // destructors release held pointers on leaving scope // деструкторы освобождают удерживаемые указатели при // выходе из области действия } Интеллектуальные указатели выглядят очень привлекательными на первый взгляд, но могут оказаться очень опасными, так как погружают программиста в дремотное состояние; будто бы ничего страшного, относящегося к СОМ, произойти не может. Интеллектуальные указатели действительно решают реальные проблемы, особенно связанные с исключениями; однако при неосторожном употреблении они могут внести столько же дефектов, сколько они предотвращают. Например, многие интеллектуальные указатели позволяют вызывать любой метод интерфейса через оператор интеллектуального указателя –>. К сожалению, это позволяет клиенту вызывать Release с помощью этого оператора-стрелки без сообщения базовому интеллектуальному указателю о том, что его автоматический вызов Release в его деструкторе теперь является излишним и недопустимым. Оптимизация QueryInterfaceФактически реализация QueryInterface, показанная ранее в этой главе, очень проста и легко может поддерживаться любым программистом, имеющим хоть некоторое представление о СОМ и C++. Тем не менее, многие среды и каркасы приложений поддерживают реализацию, управляемую данными. Это помогает достичь большей расширяемости и эффективности благодаря уменьшению размера кода. Такие реализации предполагают, что каждый совместимый с СОМ класс предусматривает таблицу, которая отображает каждый поддерживаемый IID на какой-нибудь аспект объекта, используя фиксированные смещения или какие-то другие способы. В сущности, реализация QueryInterface , приведенная ранее в этой главе, строит таблицу, основанную на скомпилированном машинном коде для каждого из последовательных операторов if, а фиксированные смещения вычисляются с использованием оператора staticcast (staticcast просто добавляет смещение базового класса, чтобы найти совместимый с типом указатель vptr). Чтобы реализовать управляемый таблицей QueryInterface, необходимо сначала определить, что эта таблица будет содержать. Как минимум, каждый элемент таблицы должен содержать указатель на IID и некое дополнительное состояние, которое позволит реализации найти указатель vptr объекта для запрошенного интерфейса. Хранение указателя функции в каждом элементе таблицы придаст этому способу максимальную гибкость, так как это даст возможность добавлять новые методики поиска интерфейсов к обычному вычислению смещения, которое используется для приведения к базовому классу. Исходный код в приложении к данной книге содержит заголовочный файл inttable.h , который определяет элементы таблицы интерфейсов следующим образом: // inttable.h (book-specific header file) // inttable.h (заголовочный файл, специфический для этой книги) // typedef for extensibility function // typedef для функции расширяемости typedef HRESULT (*INTERFACEFINDER) (void *pThis, DWORD dwData, REFIID riid, void **ppv); // pseudo-function to indicate entry is just offset // псевдофункция для индикации того, что запись просто // является смещением #define ENTRYISOFFSET INTERFACEFINDER(-1) // basic table layout // представление базовой таблицы typedef struct INTERFACEENTRY { const IID * pIID; // the IID to match // соответствующий IID INTERFACEFINDER pfnFinder; // функция finder DWORD dwData; // offset/aux data // данные по offset/aux } INTERFACEENTRY; Заголовочный файл также содержит следующие макросы для создания интерфейсных таблиц внутри определения класса: // Inttable.h (book-specific header file) // Inttable.h (заголовочный файл, специфический для данной книги) #define BASEOFFSET(ClassName, BaseName) \ (DWORD(staticcast<BaseName*>(reinterpretcast\ <ClassName*>(0x10000000))) – 0х10000000) #define BEGININTERFACETABLE(ClassName) \ typedef ClassName ITCls;\ const INTERFACEENTRY *GetInterfaceTable(void) {\ static const INTERFACEENTRY table [] = {\ #define IMPLEMENTSINTERFACE(Itf) \ {&IID##Itf,ENTRYISOFFSET,BASEOFFSET(ITCls,Itf)}, #define IMPLEMENTSINTERFACEAS(req, Itf) \ {&IID##req,ENTRYISOFFSET, BASEOFFSET(ITCls, Itf)}, #define ENDINTERFACETABLE() \ { 0, 0, 0 } }; return table; } Все, что требуется, – это стандартная функция, которая может анализировать интерфейсную таблицу в ответ на запрос QueryInterface. Такая функция содержится в файле Inttable.h: // inttable.cpp (book-specific source file) // inttable.h (заголовочный файл, специфический для данной книги) HRESULT InterfaceTableQueryInterface(void *pThis, const INTERFACEENTRY *pTable, REFIID riid, void **ppv) { if (InlineIsEqualGUID(riid, IIDIUnknown)) { // first entry must be an offset // первый элемент должен быть смещением *ppv = (char*)pThis + pTable->dwData; ((Unknown*) (*ppv))->AddRef () ; // A2 return SOK; } else { HRESULT hr = ENOINTERFACE; while (pTable->pfnFinder) { // null fn ptr == EOT if (!pTable->pIID || InlineIsEqualGUID(riid,*pTable->pIID)) { if (pTable->pfnFinder == ENTRYISOFFSET) { *ppv = (char*)pThis + pTable->dwData; ((IUnknown*)(*ppv))->AddRef(); // A2 hr = SOK; break; } else { hr = pTable->pfnFinder(pThis, pTable->dwData, riid, ppv); if (hr == SOK) break; } } pTable++; } if (hr!= SOK) *ppv = 0; return hr; } } Получив указатель на запрошенный объект, InterfaceTableQueryInterface сканирует таблицу в поисках элемента, соответствующего запрошенному IID, и либо добавляет соответствующее смещение, либо вызывает соответствующую функцию. Приведенный выше код использует усовершенствованную версию IsEqualGUID, которая генерирует несколько больший код, но результаты по скорости примерно на 20-30 процентов превышают данные по существующей реализации, которая не управляется таблицей. Поскольку код для InterfaceTableQueryInterface появится в исполняемой программе только один раз, это весьма неплохой компромисс. Очень легко автоматизировать поддержку СОМ для любого класса C++, основанную на таком табличном управлении, простым использованием С-препроцессора. Следующий фрагмент из заголовочного файла impunk.h определяет QueryInterface, AddRef и Release для объекта, использующего интерфейсные таблицы и расположенного в динамически распределяемой области памяти: // impunk.h (book-specific header file) // impunk.h (заголовочный файл, специфический для данной книги) // AUTOLONG is just a long that constructs to zero // AUTOLONG – это просто long, с конструктором, // устанавливающим значение в О struct AUTOLONG { LONG value; AUTOLONG (void) : value (0) {} }; #define IMPLEMENTUNKNOWN(ClassName) \ AUTOLONG mcRef; \ STDMETHODIMP QueryInterface(REFIID riid, void **ppv){ \ return InterfaceTableQueryInterface(this, \ GetInterfaceTable(), riid, ppv); \ } \ STDMETHODIMP(ULONG) AddRef(void) { \ return InterlockedIncrement(&mcRef.value); \ } \ STDMETHODIMP(ULONG) Release(void) { \ ULONG res = InterlockedDecrement(&mcRef.value) ; \ if (res == 0) \ delete this; \ return res; \ } Настоящий заголовочный файл содержит дополнительные макросы для поддержки объектов, не находящихся в динамически распределяемой области памяти. Для реализации примера PugCat, уже встречавшегося в этой главе, необходимо всего лишь удалить текущие реализации QueryInterface, AddRef и Release и добавить соответствующие макросы: class PugCat : public IPug, public ICat { protected: virtual ~PugCat(void); public: PugCat(void); // IUnknown methods // методы IUnknown IMPLEMENTUNKNOWN (PugCat) BEGININTERFACETABLE(PugCat) IMPLEMENTSINTERFACE(IPug) IMPLEMENTSINTERFACE(IDog) IMPLEMENTSINTERFACEAS(IAnimal,IDog) IMPLEMENTSINTERFACE(ICat) ENDINTERFACETABLE() // IAnimal methods // методы IAnimal STDMETHODIMP Eat(void); // IDog methods // методы IDog STDMETHODIMP Bark(void); // IPug methods // методы IPug STDMETHODIMP Snore(void); // ICat methods // методы ICat STDMETHODIMP IgnoreMaster(void); }; Когда используются эти макросы препроцессора, для поддержки IUnknown не требуется никакого дополнительного кода. Все, что осталось сделать, это реализовать текущие методы интерфейса, которые делают этот класс уникальным. Типы данныхВсе интерфейсы СОМ должны быть определены в IDL. IDL позволяет описывать довольно сложные типы данных в стиле, не зависящем от языка и платформы. Рисунок 2.6 показывает базовые типы, которые поддерживаются IDL, и их отображения в языки С, Java и Visual Basic. Целые и вещественные типы не требуют объяснений. Первые «интересные» типы данных, встречающиеся при программировании в СОМ, – это символы и строки. 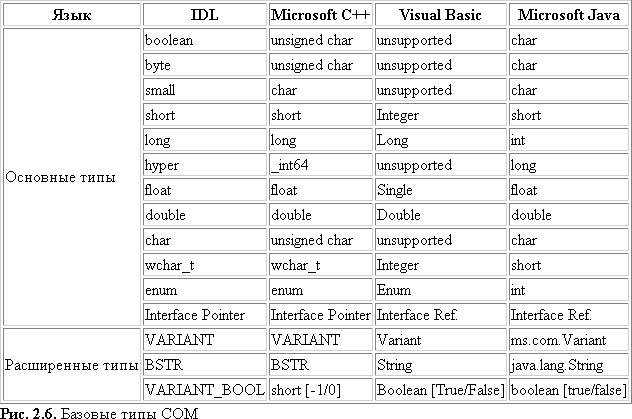 Все символы в СОМ представлены с использованием типа данных OLECHAR. Для Windows NT, Windows 95, Win32s и Solaris OLECHAR – это просто typedef для типа данных С wchar_t. Специфика других платформ описана в соответствующих документациях. Платформы Win32 используют тип данных wchar_t для представления 16-битных символов Unicode[1]. Поскольку типы указателей в IDL созданы так, что указывают на одиночные переменные, а не на массивы, то IDL вводит атрибут [string], чтобы подчеркнуть, что указатель указывает на массив-строку с завершающим нулем: HRESULT Method([in, string] const OLECHAR *pwsz); Для определения строк и символов, совместимых с OLECHAR, в СОМ введен макрос OLESTR, который приписывает букву L перед строковой или символьной константой, информируя таким образом компилятор о том, что эта константа имеет тип wchar_t. Например, правильным будет такой способ инициализировать указатель OLECHAR с помощью строкового литерала: const OLECHAR *pwsz = OLESTR(«Hello»); Под Win32 или Solaris это эквивалентно const wchar_t *pwsz = L"Hello"; Первый вариант предпочтительней, так как он будет надежно компилироваться на всех платформах. Поскольку часто возникает необходимость копировать строки на основе типа wchar_t в обычные буфера на основе char, то динамическая библиотека С предлагает две процедуры для преобразования типов: size_t mbstowcs(wchar_t *pwsz, const char *psz, int cch); size_t wcstombs(char *psz, const wchar_t *pwsz, int cch); Эти две процедуры работают аналогично динамической С-процедуре strncpy, за исключением того, что в эти процедуры как часть операции копирования включено расширение или сужение строки. Следующий код показывает, как параметр метода, размещенный в OLECHAR, можно скопировать в элемент данных, размещенный в char: class BigDog : public ILabrador { char m_szName[1024] ; public: STDMETHODIMP SetName(/* [in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверяем переполнение буфера или неверное преобразование if (cb == sizeof(m_szName) || cb == (size_t)-1) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } }; Этот код является довольно простым, хотя программист должен осознавать, что используются два различных типа символов. Несколько более сложный (и чаще встречающийся) случай – преобразование между типами данных OLECHAR и TCHAR из Win32. Так как OLECHAR условно компилируется как char или wchar_t, то при реализации метода необходимо должным образом рассмотреть оба сценария: class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName( /*[in,string]*/ const OLECHAR *pwsz) { HRESULT hr = S_OK; #ifdef UNICODE // Unicode build (TCHAR == wchar_t) // конструкция Unicode (TCHAR == wchar_t) wcsncpy(m_szName, pwsz, 1024); // check for buffer overflow // проверка на переполнение буфера if (m_szName[1023] != 0) { m_szName[0] = 0; hr = E_INVALIDARG; } #else // Non-Unicode build (TCHAR == char) // не является конструкцией Unicode (TCHAR == char) size_t cb = wcstombs(m_szName, pwsz, 1024); // check for buffer overflow or bad conversion // проверка переполнения буфера или ошибки преобразования if (cb == sizeof(m_szName) || cb == (size_t)-1) { m_szName[0] =0; hr = E_INVALIDARG; } #endif return hr; } }; Очевидно, операции с преобразованиями OLECHAR в TCHAR значительно сложнее. Но, к сожалению, это самый распространенный сценарий при программировании в СОМ на базе Win32. Одним из подходов к упрощению преобразования текста является применение системы типов C++ и использование перегрузки функций для выбора нужной строковой процедуры, построенной на типах параметров. Заголовочный файл ustring.h из приложения к этой книге содержит семейство библиотечных строковых процедур, аналогичных стандартным библиотечным процедурам С, которые находятся в файле string.h. Например, функция strncpy имеет четыре соответствующих процедуры, зависящие от каждого из параметров, которые могут быть одного из двух символьных типов (wchar_t или char): // from ustring.h (book-specific header) // из ustring.h (заголовок, специфический для данной книги) inline bool ustrncpy(char *p1, const wchar_t *p2, size_t c) { size_t cb = wcstombs(p1, p2, c); return cb != c && cb != (size_t)-1; }; inline bool ustrncpy(wchar_t *p1, const wchar_t *p2, size_t c) { wcsncpy(p1, p2, c); return p1[c – 1] == 0; }; inline bool ustrncpy(char *p1, const char *p2, size_t c) { strncpy(p1, p2, c); return p1[c – 1] == 0; }; inline bool ustrncpy(wchar_t *p1, const char *p2, size_t c) { size_t cch = mbstowcs(p1, p2, c); return cch != c && cch != (size_t)-1; } Отметим, что для любого сочетания типов идентификаторов может быть найдена соответствующая перегруженная функция ustrncpy, причем результат показывает, была или нет вся строка целиком скопирована или преобразована. Поскольку эти процедуры определены как встраиваемые (inline) функции, их использование не внесет никаких затрат при выполнении. С этими процедурами предыдущий фрагмент кода станет значительно проще и не потребует условной компиляции: class BigDog : public ILabrador { TCHAR m_szName[1024]; // note TCHAR-based string // отметим строку типа TCHAR public: STDMETHODIMP SetName(/* [in,string] */ const OLECHAR *pwsz) { HRESULT hr = S_OK; // use book-specific overloaded ustrncpy to copy or convert // используем для копирования и преобразования // перегруженную функцию ustrncpy, специфическую для данной книги if (!ustrncpy(m_szName, pwsz, 1024)) { m_szName[0] = 0; hr = E_INVALIDARG; } return hr; } }; Соответствующие перегруженные функции для процедур strlen, strcpy и strcat также включены в заголовочный файл ustring.h. Использование перегрузки библиотечных функций для копирования строк из одного буфера в другой, как это показано выше, обеспечивает лучшее качество исполнения, уменьшает размер кода и непроизводительные издержки программиста. Однако часто возникает ситуация, когда одновременно используются СОМ и API-функции Win32, что не дает возможности применить эту технику. Рассмотрим следующий фрагмент кода, читающий строку из элемента редактирования и преобразующий ее в IID: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; // call a TCHAR-based Win32 routine // вызываем TCHAR-процедуру Win32 GetWindowText(hwnd, szEditText, 1024); // call an OLECHAR-based СОМ routine // вызываем OLECHAR-процедуру СОМ return IIDFromString(szEditText, &riid); } Допуская, что этот код скомпилирован с указанным символом С-препроцессора UNICODE; он работает безупречно, так как TCHAR и OLECHAR являются просто псевдонимами wchar_t и никакого преобразования не требуется. Если же функция скомпилирована с версией Win32 API, не поддерживающей Unicode, то TCHAR является псевдонимом для char, и первый параметр для IIDFromString имеет неправильный тип. Чтобы решить эту проблему, нужно провести условную компиляцию: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); #ifdef UNICODE return IIDFromString(szEditText, &riid); #else OLECHAR wszEditText[l024]; ustrncpy(wszEditText, szEditText, 1024); return IIDFromString(wszEditText, &riid); #endif } Хотя этот фрагмент и генерирует оптимальный код, очень утомительно применять эту технику всякий раз, когда символьный параметр имеет неверный тип. Можно справиться с этой проблемой, если использовать промежуточный (shim) класс с конструктором, принимающим в качестве параметра любой тип символьной строки. Этот промежуточный класс должен также содержать в себе операторы приведения типа, что позволит использовать его в обоих случаях: когда ожидается const char * или const wchar_t *. В этих операциях приведения промежуточный класс либо выделяет резервный буфер и производит необходимое преобразование, либо просто возвращает исходную строку, если преобразования не требовалось. Деструктор промежуточного класса может затем освободить все выделенные буферы. Заголовочный файл ustring.h содержит два таких промежуточных класса: _U и _UNCC. Первый предназначен для нормального использования; второй используется с функциями и методами, тип аргументов которых не включает спецификатора const[2] (таких как IIDFromString). При возможности применения двух промежуточных классов предыдущий фрагмент кода может быть значительно упрощен: HRESULT IIDFromHWND(HWND hwnd, IID& riid) { TCHAR szEditText[1024]; GetWindowText(hwnd, szEditText, 1024); // use _UNCC shim class to convert if necessary // используем для преобразования промежуточный класс _UNCC, // если необходимо return IIDFromString(_UNCC(szEditText), &riid); } Заметим, что не требуется никакой условной компиляции. Если код скомпилирован с версией Win32 с поддержкой Unicode, то класс _UNCC просто пропустит исходный буфер через свой оператор приведения типа. Если же код компилируется с версией Win32, не поддерживающей Unicode, то класс _UNCC выделит буфер и преобразует строку в Unicode. Затем деструктор _UNCC освободит буфер, когда операция будет выполнена полностью[3]. Следует обсудить еще один дополнительный тип данных, связанный с текстом, – BSTR. Строковый тип BSTR нужно применять во всех интерфейсах, которые предполагается использовать из языков Visual Basic или Java. Строки BSTR являются OLECHAR-строками с префиксом длины (length-prefix) в начале строки и нулем в ее конце. Префикс длины показывает число байт, содержащихся в строке (исключая завершающий нуль) и записан в форме четырехбайтового целого числа, непосредственно предшествующего первому символу строки. Рисунок 2.7 демонстрирует BSTR на примере строки «Hi». Чтобы позволить методам свободно возвращать строки BSTR без заботы о выделении памяти, все BSTR размещены с помощью распределителя памяти, управляемого СОМ. В СОМ предусмотрено несколько API-функций для управления BSTR: 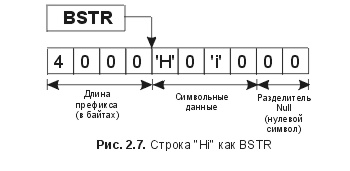 // from oleauto.h // allocate and initialize a BSTR // выделяем память и инициализируем строку BSTR BSTR SysAllocString(const OLECHAR *psz); BSTR SysAllocStringLen(const OLECHAR *psz, UINT cch); // reallocate and initialize a BSTR // повторно выделяем память и инициализируем BSTR INT SysReAllocString(BSTR *pbstr, const OLECHAR *psz); INT SysReAllocStringLen(BSTR *pbstr, const OLECHAR * psz, UINT cch); // free a BSTR // освобождаем BSTR void SysFreeString(BSTR bstr); // peek at length-prefix as characters or bytes // считываем префикс длины как число символов или байт UINT SysStringLen(BSTR bstr); UINT SysStringByteLen(BSTR bstr); При пересылке строк методу в качестве параметров типа [in] вызывающий объект должен заботиться о том, чтобы вызвать SysAllocString прежде, чем запускать сам метод, и чтобы вызвать SysFreeString после того, как метод закончил работу. Рассмотрим следующее определение метода: HRESULT SetString([in] BSTR bstr); Пусть в вызывающей программе уже имеется строка, совместимая с OLECHAR, тогда для того, чтобы преобразовать строку в BSTR до вызова метода, необходимо следующее: // convert raw OLECHAR string to a BSTR // преобразовываем «сырую» строку OLECHAR в строку BSTR BSTR bstr = SysAllocString(OLESTR(«Hello»)); // invoke method // вызываем метод HRESULT hr = p->SetString(bstr); // free BSTR // освобождаем BSTR SysFreeString(bstr); Промежуточный класс для работы с BSTR, _UBSTR, включен в заголовочный файл ustring.h: // from ustring.h (book-specific header file) // из ustring.h (специфический для данной книги заголовочный файл) class _UBSTR { BSTR m_bstr; public: _UBSTR(const char *psz) : m_bstr(SysAllocStringLen(0, strlen(psz))) { mbstowcs(m_bstr, psz, INT_MAX); } _UBSTR(const wchar_t *pwsz) : m_bstr(SysAllocString(pwsz)) { } operator BSTR (void) const { return m_bstr; } ~_UBSTR(void) { SysFreeString(m_bstr); } }; При наличии такого промежуточного класса предыдущий фрагмент кода значительно упростится: // invoke method // вызываем метод HRESULT hr = p->SetString(_UBSTR(OLESTR(«Hello»))); Заметим, что в промежуточном классе UBSTR могут быть в равной степени использованы строки типов char и wchar_t. При передаче из метода строк через параметры типа [out] объект обязан вызвать SysAllocString, чтобы записать результирующую строку в буфер. Затем вызывающий объект должен освободить буфер путем вызова SysFreeString. Рассмотрим следующее определение метода: HRESULT GetString([out, retval] BSTR *pbstr); При реализации метода потребуется создать новую BSTR-строку для возврата вызывающему объекту: STDMETHODIMP MyClass::GetString(BSTR *pbstr) { *pbstr = SysAllocString(OLESTR(«Coodbye!»)) ; return S_OK; } Теперь вызывающий объект должен освободить строку сразу после того, как она скопирована в управляемый приложением строковый буфер: extern OLECHAR g_wsz[]; BSTR bstr = 0; HRESULT hr = p->GetString(&bstr); if (SUCCEEDED(hr)) { wcscpy(g_wsz, bstr); SysFreeString(bstr); } Тут нужно рассмотреть еще один важный аспект BSTR. В качестве BSTR можно передать нулевой указатель, чтобы указать на пустую строку. Это означает, что предыдущий фрагмент кода не совсем корректен. Вызов wcscpy: wcscpy(g_wsz, bstr); должен быть защищен от возможных нулевых указателей: wcscpy (g_wsz, bstr ? bstr : OLESTR("")); Для упрощения использования BSTR в заголовочном файле ustring.h содержится простая встраиваемая функция: intline OLECHAR *SAFEBSTR(BSTR b) { return b ? b : OLESTR(""); } Разрешение использовать нулевые указатели в качестве BSTR делает тип данных более эффективным с точки зрения использования памяти, хотя и приходится засорять код этими простыми проверками. Простые типы, показанные на рис. 2.6, могут компоноваться вместе с применением структур языка С. IDL подчиняется правилам С для пространства имен тегов (tag namespace). Это означает, что большинство IDL-определений интерфейсов либо используют операторы определения типа (typedef): typedef struct tagCOLOR { double red; double green; double blue; } COLOR; HRESULT SetColor([in] const COLOR *pColor); либо должны использовать ключевое слово struct для квалификации имени тега: struct COLOR { double red; double green; double blue; }; HRESULT SetColor([in] const struct COLOR *pColor); Первый вариант предпочтительней. Простые структуры, подобные приведенной выше, можно использовать как из Visual Basic, так и из Java. Однако в то время, когда пишется эта книга, текущая версия Visual Basic может обращаться только к интерфейсам, использующим структуры, но она не может быть использована для реализации интерфейсов, в которых структуры являются параметрами методов. IDL и СОМ поддерживают также объединения (unions). Для обеспечения однозначной интерпретации объединения IDL требует, чтобы в этом объединении имелся дискриминатор (discriminator), который показывал бы, какой именно член объединения используется в данный момент. Этот дискриминатор должен быть целого типа (integral type) и должен появляться на том же логическом уровне, что и само объединение. Если объединение объявлено вне области действия структуры, то оно считается неинкапсулированным (nonencapsulated): union NUMBER { [case(1)] long i; [case(2)] float f; }; Атрибут [case] применен для установления соответствия каждого члена объединения своему дискриминатору. Для того чтобы связать дискриминатор с неинкапсулированным объединением, необходимо применить атрибут [switch_is]: HRESULT Add([in, switch_is(t)] union NUMBER *pn, [in] short t); Если объединение заключено вместе со своим дискриминатором в окружающую структуру, то этот составной тип (aggregate type) называется инкапсулированным, или размеченным объединением (discriminated union): struct UNUMBER { short t; [switch_is(t)] union VALUE { [case(1)] long i; [case(2)] float f; }; }; СОМ предписывает для использования с Visual Basic одно общее размеченное объединение. Это объединение называется VARIANT[4] и может хранить объекты или ссылки на подмножество базовых типов, поддерживаемых IDL. Каждому из поддерживаемых типов присвоено соответствующее значение дискриминатора: VT_EMPTY nothing VT_NULL SQL style Null VT_I2 short VT_I4 long VT_R4 float VT_R8 double VT_CY CY (64-bit currency) VT_DATE DATE (double) VT_BSTR BSTR VT_DISPATCH IDispatch * VT_ERROR HRESULT VT_BOOL VARIANT_BOOL (True=-1, False=0) VT_VARIANT VARIANT * VT_UNKNOWN IUnknown * VT_DECIMAL 16 byte fixed point VT_UI1 opaque byte Следующие два флага можно использовать в сочетании с вышеприведенными тегами, чтобы указать, что данный вариант (variant) содержит ссылку или массив данного типа: VT_ARRAY Указывает, что вариант содержит массив SAFEARRAY VT_BYREF Указывает, что вариант является ссылкой СОМ предлагает несколько API-функций для управления VARIANT: // initialize a variant to empty // обнуляем вариант void VariantInit(VARIANTARG * pvarg); // release any resources held in a variant // освобождаем все ресурсы, используемые в варианте HRESULT VariantClear(VARIANTARG * pvarg); // deep-copy one variant to another // полностью копируем один вариант в другой HRESULT VariantCopy(VARIANTARG * plhs, VARIANTARG * prhs); // dereference and deep-copy one variant into another // разыменовываем и полностью копируем один вариант в другой HRESULT VariantCopyInd(VARIANT * plhs, VARIANTARG * prhs); // convert a variant to a designated type // преобразуем вариант к указанному типу HRESULT VariantChangeType(VARIANTARG * plhs, VARIANTARG * prhs, USHORT wFlags, VARTYPE vtlhs); // convert a variant to a designated type // преобразуем вариант к указанному типу (с явным указанием кода локализации) HRESULT VariantChangeTypeEx(VARIANTARG * plhs, VARIANTARG * prhs, LCID lcid, USHORT wFlags, VARTYPE vtlhs); Эти функции значительно упрощают управление VARIANT'ами. Чтобы понять, как используются эти API-функции, рассмотрим метод, принимающий VARIANT в качестве [in]-параметра: HRESULT UseIt([in] VARIANT var); Следующий фрагмент кода демонстрирует, как передать в этот метод целое число: VARIANT var; VariantInit(&var); // initialize VARIANT // инициализируем VARIANT V_VT(&var) = VT_I4; // set discriminator // устанавливаем дискриминатор V_I4(&var) = 100; // set union // устанавливаем объединение HRESULT hr = pItf->UseIt(var); // use VARIANT // используем VARIANT VariantClear(&var); // free any resources in VARIANT // освобождаем все ресурсы VARIANT Отметим, что этот фрагмент кода использует макросы стандартного аксессора (accessor) для доступа к элементам данных VARIANT. Две следующие строки V_VT(&var) = VT_I4; V_I4(&var) = 100; эквивалентны коду, который обращается к самим элементам данных: var.vt = VT_I4; var.lVal = 100; Первый вариант предпочтительнее, так как он может компилироваться на С-трансляторах, которые не поддерживают неименованных объединений. Ниже приведен пример того, как с помощью приведенной выше технологии реализация метода использует параметр VARIANT в качестве строки: STDMETHODIMP MyClass::UseIt( /*[in] */ VARIANT var) { // declare and init a second VARIANT // объявляем и инициализируем второй VARIANT VARIANT var2; VariantInit(&var2); // convert var to a BSTR and store it in var2 // преобразуем переменную в BSTR и заносим ее в var2 HRESULT hr = VariantChangeType(&var2, &var, 0, VT_BSTR); // use the string // используем строку if (SUCCEEDED(hr)) { ustrcpy(m_szSomeDataMember, SAFEBSTR(V_BSTR(&var2))); // free any resources held by var2 // освобождаем все ресурсы, поддерживаемые var2 VariantClear(&var2); } return hr; } Отметим, что API-процедура VariantChangeType способна осуществлять сложное преобразование любого переданного клиентом типа из VARIANT в нужный тип (в данном случае BSTR). Один из последних типов данных, который вызывает дискуссию, – это интерфейс СОМ. Интерфейсы СОМ могут быть переданы в качестве параметров метода одним из двух способов. Если тип интерфейсного указателя известен на этапе проектирования, то тип интерфейса может быть объявлен статически: HRESULT GetObject([out] IDog **ppDog); Если же тип на этапе проектирования неизвестен, то разработчик интерфейса может дать пользователю возможность задать тип на этапе выполнения. Для поддержки динамически типизируемых интерфейсов в IDL имеется атрибут [iid_is]: HRESULT GetObject([in] REFIID riid, [out, iid_is(riid)] IUnknown **ppUnk); Хотя эта форма будет работать вполне хорошо, следующий вариант предпочтительнее из-за его подобия с QueryInterface: HRESULT GetObject([in] REFIID riid, [out, iid_is(riid)] void **ppv); Атрибут [iid_is] можно использовать как с параметрами [in], так и [out] для типов IUnknown * или void *. Для того чтобы использовать параметр интерфейса с динамически типизируемым типом, необходимо просто установить IID указателя требуемого типа: IDog *pDog = 0; HRESULT hr = pItf->GetObject(IID_IDog, (void**)&pDog); Соответствующая реализация для инициализации этого параметра просто использовала бы метод QueryInterface для нужного объекта: STDMETHODIMP Class::GetObject(REFIID riid, void **ppv) { extern IUnknown * g_pUnkTheDog; return g_pUnkTheDog->QueryInterface(riid, ppv); } Для уменьшения количества дополнительных вызовов методов между клиентом и объектом указатели интерфейса с динамически типизируемым типом должны всегда использоваться вместо указателей интерфейса со статически типизируемым типом IUnknown. Атрибуты и свойстваИногда бывает полезно показать, что объект имеет некие открытые свойства, которые могут быть доступны и/или которые можно модифицировать через СОМ-интерфейс. СОМ IDL позволяет аннотировать методы интерфейса с тем, чтобы данный метод либо модифицировал, либо читал именованный атрибут объекта. Рассмотрим такое определение интерфейса: [ object, uuid(0BB3DAE1-11F4-11d1-8C84-0080C73925BA) ] interface ICollie : IDog { // Age is a read-only property // Age (возраст) – это свойство только для чтения [propget] HRESULT Age([out, retval] long *pVal); // HairCount is a read/write property // HairCount (счетчик волос) – свойство для чтения/записи [propget] HRESULT HairCount([out, retval] long *pVal); [propput] HRESULT HairCount([in] long val); // CurrentThought is a write-only property // CurrentThought (текущая мысль) – свойство только для записи [propput] HRESULT CurrentThought([in] BSTR val); } Использование атрибутов [propget] и [propput] информирует компилятор IDL, что методы, которые ему соответствуют, должны быть отображены в преобразователи свойств (property mutators) или в аксессоры на языках, явно поддерживающих свойства. Применительно к Visual Basic это означает, что элементами Age, HairCount и CurrentThought можно манипулировать, используя тот же синтаксис, как при обращении к элементам структуры: Sub UseCollie(fido as ICollie) fido.HairCount = fido.HairCount – (fido.Age * 1000) fido.CurrentThought = «I wish I had a bone» End Sub С++-отображение этого интерфейса просто прибавляет к именам методов конструкции put или get, чтобы подсказать программисту, что обращение относится к свойству: void UseCollie(ICollie *pFido) { long n1, n2; HRESULT hr = pFido->getHairCount(&n1); assert(SUCCEEDED(hr)); hr = pFido->getAge(&n2); assert(SUCCEEDED(hr)); hr = pFido->putHairCount(n1 – (n2 * 1000)): assert(SUCCEEDED(hr)); BSTR bstr = SysAllocString(OLESTR(«I wish I had a bone»)); hr = pFido->putCurrentThought(bstr); assert(SUCCEEDED(hr)); SysFreeString(bstr); } Хотя свойства напрямую не обеспечивают развития, они полезны для выполнения точных преобразований на те языки, которые их поддерживают[1]. ИсключенияСОМ имеет специфическую поддержку выбрасывания (throwing) исключительных ситуаций из реализации методов. Поскольку в языке C++ не существует двоичного стандарта для исключений, СОМ предлагает явные API-функции для выбрасывания и перехвата объектов СОМ-исключений: // throw an exception // возбуждаем исключения HRESULT SetErrorInfo([in] ULONG reserved, // m.b.z. [in] IErrorlnfo *pei); // catch an exception // перехватываем исключение HRESULT GetErrorInfo([in] ULONG reserved, // m.b.z. [out] IErrorInfo **ppei); Процедура SetErrorInfo вызывается из реализации метода, чтобы связать объект исключения с текущим логическим потоком (logical thread)[1]. GetErrorInfo выбирает объект исключения из текущего логического потока и сбрасывает исключение, так что следующие вызовы GetErrorInfo возвратят SFALSE, показывая тем самым, что необработанных исключений нет. Как следует из приведенных ниже подпрограмм, объекты исключений должны поддерживать по крайней мере интерфейс IErrorInfo: [ object, uuid(1CF2B120-547D-101B-8E65-08002B2BD119) ] interface IErrorInfo: IUnknown { // get IID of interface that threw exception // получаем IID того интерфейса, который возбудил исключение HRESULT GetGUID([out] GUID * pGUID); // get class name of object that threw exception // получаем имя класса того объекта, который возбудил исключение HRESULT GetSource([out] BSTR * pBstrSource); // get human-readable description of exception // получаем читабельное описание исключения HRESULT GetDescription([out] BSTR * pBstrDescription); // get WinHelp filename of documentation of error // получаем имя файла WinHelp, содержащего документацию об ошибке HRESULT GetHelpFile([out] BSTR * pBstrHelpFile); // get WinHelp context ID for documentation of error // получаем контекстный идентификатор WinHelp для документации ошибки HRESULT GetHelpContext([out] DWORD * pdwHelpContext); } Специальные объекты исключений могут выбрать другие специфические для исключений интерфейсы в дополнение к IErrorInfo. СОМ предусматривает по умолчанию реализацию IErrorInfo, которую можно создать с использованием API-функции СОМ CreateErrorInfo: HRESULT CreateErrorInfo([out] ICreateErrorInfo **ppcei); В дополнение к IErrorInfo объекты исключений по умолчанию открывают интерфейс ICreateErrorInfo, чтобы позволить пользователю инициализировать состояние нового исключения: [ object, uuid(22F03340-547D-101B-8E65-08002B2BD119) ] interface ICreateErrorInfo: IUnknown { // set IID of interface that threw exception // устанавливаем IID интерфейс, который возбудил исключение HRESULT SetGUID([in] REFGUID rGUID); // set class name of object that threw exception // устанавливаем классовое имя объекта, который возбудил исключение HRESULT SetSource([in, string] OLECHAR* pwszSource); // set human-readable description of exception // устанавливаем читабельное описание исключения HRESULT SetDescription([in, string] OLECHAR* pwszDesc); // set WinHelp filename of documentation of error // устанавливаем имя файла WinHelp, содержащего документацию об ошибке HRESULT SetHelpFile([in, string] OLECHAR* pwszHelpFile); // set WinHelp context ID for documentation of error // устанавливаем идентификатор контекста WinHelp для документации ошибки HRESULT SetHelpContext([in] DWORD dwHelpContext); } Заметим, что этот интерфейс просто позволяет пользователю заполнить объект исключения пятью основными атрибутами, доступными из интерфейса IErrorInfo. Следующая реализация метода выбрасывает СОМ-исключение своему вызывающему объекту, используя объект исключений по умолчанию: STDMETHODIMP PugCat::Snore(void) { if (this->IsAsleep()) // ok to perform operation? // можно ли выполнять операцию? return this->DoSnore(); //do operation and return // выполняем операцию и возвращаемся //otherwise create an exception object // в противном случае создаем объект исключений ICreateErrorInfo *рсеi = 0; HRESULT hr = CreateErrorInfo(&pcei); assert(SUCCEEDED(hr)); // initialize the exception object // инициализируем объект исключений hr = pcei->SetGUID(IIDIPug); assert(SUCCEEDED(hr)); hr = pcei->SetSource(OLESTR(«PugCat»)); assert(SUCCEEDED(hr)); hr = pcei->SetDescription(OLESTR("I am not asleep!")); assert(SUCCEEDED(hr)); hr = pcei->SetHelpFile(OLESTR(«C:\\PugCat.hlp»)); assert(SUCCEEDED(hr)); hr = pcei->SetHelpContext(5221); assert(SUCCEEDED(hr)); // «throw» exception // «выбрасываем» исключение IErrorInfo *pei = 0; hr = pcei->QueryInterface(IIDIErrorInfo, (void**)&pei); assert(SUCCEEDED(hr)); hr = SetErrorInfo(0, pei); // release resources and return a SEVERITYERROR result // высвобождаем ресурсы и возвращаем результат // SEVERITYERROR (серьезность ошибки) pei->Release(); pcei->Release(); return PUGEPUGNOTASLEEP; } Отметим, что поскольку объект исключений передается в процедуру SetErrorInfo, СОМ сохраняет ссылку на исключение до тех пор, пока оно не будет «перехвачено» вызывающим объектом, использующим GetErrorInfo. Объекты, которые сбрасывают исключения СОМ, должны использовать интерфейс ISupportErrorInfo , чтобы показывать, какие интерфейсы поддерживают исключения. Этот интерфейс используется клиентами, чтобы установить, верный ли результат дает GetErrorInfo[2]. Этот интерфейс предельно прост: [ object, uuid(DFOB3060-548F-101B-8E65-08002B2BD119) ] interface ISupportErrorInfo: IUnknown { HRESULT InterfaceSupportsErrorInfo([in] REFIID riid); } Предположим, что класс PugCat, рассмотренный в этой главе, сбрасывает исключения из каждого поддерживаемого им интерфейса. Тогда его реализация будет выглядеть так: STDMETHODIMP PugCat::InterfaceSupportsErrorInfo(REFIID riid) { if (riid == IIDIAnimal || riid == IIDICat || riid == IIDIDog || riid == IIDIPug) return SOK; else return SFALSE; } Ниже приведен пример клиента, который надежно обрабатывает исключения, используя ISupportErrorInfo и GetErrorInfo: void TellPugToSnore(/*[in]*/ IPug *pPug) { // call a method // вызываем метод HRESULT hr = pPug->Snore(); if (FAILED(hr)) { // check to see if object supports СОМ exceptions // проверяем, поддерживает ли объект исключения СОМ ISupportErrorInfo *psei = 0; HRESULT hr2 =pPug->QueryInterface( IIDISupportErrorInfo, (void**)&psei); if (SUCCEEDED(hr2)) { // check if object supports СОМ exceptions via IPug methods // проверяем, поддерживает ли объект исключения СОМ через методы IPug hr2 = psei->InterfaceSupportsErrorInfo(IIDIPug); if (hr2 == SOK) { // read exception object for this logical thread // читаем объект исключений для этого логического потока IErrorInfo *реi = 0; hr2 = GetErrorInfo(0, &pei); if (hr2 == SOK) { // scrape out source and description strings // извлекаем строки кода и описания BSTR bstrSource = 0, bstrDesc = 0; hr2 = pei->GetDescription(&bstrDesc); assert(SUCCEEDED(hr2)); hr2 = pei->GetSource(&bstrSource); assert(SUCCEEDED(hr2)); // display error information to end-user // показываем информацию об ошибке конечному пользователю MessageBoxW(0, bstrDesc ? bstrDesc : L"«, bstrSource ? bstrSource : L»", MBOK); // free resources // высвобождаем ресурсы SysFreeString(bstrSource); SysFreeString(bstrDesc); pei->Release(); } } psei->Release(); } } if (hr2!= SOK) // something went wrong with exception // что-то неладно с исключением MessageBox(0, «Snore Failed», «IPug», MBOK); } Довольно просто отобразить исключения СОМ в исключения C++, причем в любом месте. Определим следующий класс, который упаковывает объект исключений СОМ и HRESULT в один класс C++: struct COMException { HRESULT mhresult; // hresult to return // hresult для возврата IErrorInfo *mpei; // exception to throw // исключение для выбрасывания COMException(HRESULT hresult, REFIID riid, const OLECHAR *pszSource, const OLECHAR *pszDesc, const OLECHAR *pszHelpFile = 0, DWORD dwHelpContext = 0) { // create and init an error info object // создаем и инициализируем объект информации об ошибке ICreateErrorInfo *рсеi = 0; HRESULT hr = CreateErrorInfo(&pcei); assert(SUCCEEDED(hr)); hr = pcei->SetGUID(riid); assert(SUCCEEDED(hr)); if (pszSource) hr=pcei->SetSource(constcast<OLECHAR*>(pszSource)); assert(SUCCEEDED(hr)); if (pszDesc) hr=pcei->SetDescription(constcast<OLECHAR*>(pszDesc)); assert(SUCCEEDED(hr)); if (pszHelpFile) hr=pcei->SetHelpFile(constcast<OLECHAR*>(pszHelpFile)); assert(SUCCEEDED(hr)); hr = pcei->SetHelpContext(dwHelpContext); assert(SUCCEEDED(hr)); // hold the HRESULT and IErrorInfo ptr as data members // сохраняем HRESULT и указатель IErrorInfo как элементы данных mhresult = hresult; hr=pcei->QueryInterface(IIDIErrorInfo, (void**)&mpei); assert(SUCCEEDED(hr)); pcei->Release(); } }; С использованием только что приведенного С++-класса COMException показанный выше метод Snore может быть модифицирован так, чтобы он преобразовывал любые исключения C++ в исключения СОМ: STDMETHODIMP PugCat::Snore(void) { HRESULT hrex = SOK; try { if (this->IsAsleep()) return this->DoSnore(); else throw COMException(PUGEPUGNOTASLEEP, IIDIPug, OLESTR(«PugCat»), OLESTR(«I am not asleep!»)); } catch (COMException& ce) { // a C++ COMException was thrown // было сброшено исключение COMException C++ HRESULT hr = SetErrorInfo(0, ce.mpei); assert(SUCCEEDED(hr)); ce.mpei->Release(); hrex = ce.mhresult; } catch (…) { // some unidentified C++ exception was thrown // было выброшено какое-то неидентифицированное исключение C++ COMException ex(EFAIL, IIDIPug, OLESTR(«PugCat»), OLESTR(«A C++ exception was thrown»)); HRESULT hr = SetErrorInfo(0, ex.mpei); assert(SUCCEEDED(hr)); ex.mpei->Release(); hrex = ex.mhresult; } return hrex; } Заметим, что реализация метода заботится о том, чтобы не позволить чисто С++-исключениям переходить через границы метода. Таково безусловное требование СОМ. Где мы находимся?В этой главе была представлена концепция интерфейса СОМ. Интерфейсы СОМ обладают простыми двоичными сигнатурами, которые позволяют любому клиенту обращаться к объекту независимо от языка программирования, использованного клиентом или конструктором объекта. Чтобы облегчить поддержку различных языков, интерфейсы СОМ определяются на языке IDL (Interface Definition Language). Эти IDL-определения интерфейса могут быть также использованы для генерирования кода передачи данных (communications code), который позволяет получать доступ к объекту через сеть. Большая часть этой главы была посвящена IUnknown – базовому интерфейсу, на котором построен весь СОМ. Все интерфейсы СОМ должны наследовать от IUnknown. Следовательно, все объекты СОМ должны реализовывать IUnknown. В IUnknown предусмотрено три сигнатуры метода, посредством которых клиент может безошибочно управлять иерархией типов объекта для доступа к дополнительным возможностям, предоставляемым этим объектом. С учетом этого QueryInterface можно рассматривать как оператор приведения типа в СОМ. По этой же причине IUnknown можно рассматривать как «void *» (указатель на пустой тип) среди указателей интерфейса, так как от него не слишком много пользы до тех пор, пока он не «приведен» (is «cast») к чему-нибудь более содержательному с помощью QueryInterface. Следует заметить, что при обращении или реализации IUnknown не было сделано никаких существенных системных вызовов. В этом смысле IUnknown просто является протоколом или набором обещаний (promises), которого должны придерживаться все программы. Это позволяет объектам СОМ быть очень простыми и эффективными. Реализация IUnknown в C++ требует всего нескольких строк стандартного кода. Чтобы автоматизировать реализацию IUnknown в C++, была представлена серия макросов для препроцессора, которые реализуют QueryInterface под табличным управлением. Хотя эти макросы не были совершенно необходимыми, они удаляли большую часть общего стандартного кода из каждого определения класса, не внося при этом заметных усложнений в реализацию. |
|
|||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||
|
|
||||