|
||||
|
Голубятня-Онлайн Голубятня: Чудо Compreno Сергей Голубицкий Опубликовано 28 февраля 2012 года Больше всего на свете мне хочется выделить тему сегодняшнего рассказа из потока рядовых событий IT, которыми заполняется информационное пространство моей колонки. Новые гаджеты — это замечательно. Новый удачный софт -бальзам на истерзанную душу пользователя. Проект Compreno, над которым компания ABBYY корпит уже 15 лет и выводит, дай бог, в этом году на стадию готового к потреблению продукта — это не новое, и тем более — не очередное событие. Compreno — это полноценная, не имеющая аналогов в истории технологическая революция. Масштаб этой революции, значение ее для людей (именно для всех людей, а не только для любителей компьютеров) сопоставимы разве что с изобретением World Wide Web или электронной почты. Никак не меньше. Для наглядности можно перевести эту революцию в понятные материально-купюрные реалии: если ABBYY спокойно, без суеты коммерциализирует Compreno хотя бы в десятой части возможных ее практических применений, а затем выйдет на фондовый рынок, капитализация компании затмит всех кумиров сегодняшнего дня — от Apple, грамотно и стильно эксплуатирующего весьма и весьма посредственные в технологическом отношении решения, до Google, умудряющегося заводить в тупик охапками большую часть собственных перспективных начинаний. Впрочем, довольно авансов и эмоций (хотя завсегдатаев Голубятен ни тем, ни другим давно не удивишь O — пора представить Compreno во всем его величии. Начну с лапидарного компендиума: Compreno — это технология перевода любого человеческого языка на универсальный язык понятий. Соответственно, Compreno включает в себя и сам этот универсальный язык понятий, который ABBYY 15 лет (тайком O разрабатывала в своих исследовательских лабораториях. Результат ошеломляет: Универсальная Семантическая Иерархия (УСИ) — ядро языка понятий — насчитывает сегодня 60 тысяч элементов в универсальном разделе когнитивной модели, 80 тысяч — в русском разделе, и 90 тысяч — в английском! Ничего даже отдаленного в мире не существует. Перспективы, которые открывает Compreno, безбрежны и разнообразны: - компьютеризированный перевод текста с любого языка на любой на качественном уровне, несопоставимым со всеми распространенными сегодня системами перевода; - полноценный интеллектуальный поиск без специализированного синтаксиса запросов (Поиск по смыслу, извлечение фактов и связей между объектами поиска/мониторинга; мониторинг компаний и персоналий и построение аналитических отчетов на основе параметров разного типа и др.); системы искусственного интеллекта самых разнообразных профилей и применений; - автоматическое распознавание речи; - классификация документов и поиск похожих документов по смыслу; - анализ тональности в мониторинге; - реферирование и аннотирование (написание краткого содержания длинных документов) и это только начало. За пару дней до своей индийской зимовки я встретился с Татьяной Даниэлян, заместителем директора по лингвистическим технологиям компании ABBYY, и Сергеем Андреевым, генеральным директором и президентом группы компаний ABBYY и на протяжении полных двух часов сидел, широко разинув рот и охая от восторга по мере того, как в мое сознание вливались подробности революционного проекта, подкрепленные полноценной демонстрацией действующего прототипа движков машинного перевода и системы интеллектуального поиска. Все то время, что Сергей и Татьяна, сами едва сдерживая восторг от собственных достижений, стягивали завесу тайны с Compreno, меня не покидало чувство того, что я участвую в каком-то акте добровольного промышленного шпионажа. Согласитесь, масштаб проекта ошеломляет: 15 лет интенсивной работы сотен людей, 50 миллионов долларов собственных инвестиций, совсем недавно усиленных сколковским грантом в 475 миллионов рублей. Вся компьютерная мощь головного офиса ABBYY (а он, поверьте на слово, ошеломляет: 6 этажей 7-этажногоогромного П-образного здания) в любую свободную минуту задействована для просчетов, необходимых для отладки и совершенствования Compreno, в первую очередь УСИ. Впрочем, шпионаж — это лишь в моей голове, поскольку, разумеется, беседа наша состоялась в момент, когда Abbyy вышла на финишную прямую и была готова раскрыть миру свои карты. Подробности Compreno я донесу читателям со слов Сергея Андреева и Татьяны Даниэлян — не потому, что не доверяю собственным суждениям, а потому что рассказ у обоих получился гладким и содержательным, зачем же плодить сущности? Начало разработки Compreno пришлось на 90е годы, когда в арсенале ABBYY (в те годы — еще BIT Software) уже числилось два ледокола: словари Lingvo и программа для распознавания текста FineReader. Продукты продавались по всему миру, были хитами и приносили стабильную прибыль — манна небесная для романтических проектов вроде Compreno, стресс которых не пережил бы ни один сторонний инвестор (вкладывать миллионы долларов в нечто совершенно революционное да к тому же и с неизвестными перспективами? а вдруг ничего не получится? нет уж увольте!). ABBYY обошлась без чужих денег и это спасло Compreno, позволив довести до победного конца проект со столь колоссальными материальными и людскими затратами. Успех обеспечил и правильный изначальный выбор направления для разработки системы автоматического перевода. В 90-е в мире правила одна королева — Rule-Based Translation Model, классическая модель перевода, основанная на ограниченном наборе готовых правил для некоторой пары языков. Одна из проблем RBTM — в накоплении все новых и новых правил, которые в какой-то момент просто начинают конфликтовать между собой. Анализируя предложение, мы можем применить разные комплекты правил, при этом машине неведомы приоритеты. Перевод, основанный на RBTM, как правило, не озабочен полным синтаксическим анализом: вместо него предложение делится на фреймы, на которые затем интерполируют существующие в системе правила для получения перевода. RBMT системы не учитывают семантику. В начале XXI века усилиями Google мир подсел на иглу нового алгоритма перевода — так называемой статистической модели. Основа СМ — наличие обширной базы разнонаправленных переводов. Мы задаем статистическому движку предложение для перевода, он ищет в базе данных как в словаре варианты уже существующих переводов аналогичного текста и после незначительных изменений выдает вполне приличный результат. Изменения не самые существенные. Предположим нам нужно перевести предложение «в комнате стоит красный стул», а в статистической базе уже есть переведенная фраза «в комнате стоит зеленый стол» — решение элементарно: берется уже существующий шаблон перевода и новые слова просто заменяются по словарю. Поскольку в СМ используются уже готовые человеческие переводы заведомо высокого качества, то на выходе получается весьма недурственный результат, ибо для осуществления перевода не нужно погружаться в синтаксис, специфику фразеологии конкретного языка и проч. Все замечательно, однако, лишь до тех пор, пока дело не касается переводов в направлениях с так называемым низким покрытием (скажем, каким-нибудь, румынско-русским или тайско-венгерским). Где брать аналоги? По словам Сергея Андреева опасность подстерегает также при уходе в предметные области на массовых направлениях, потому что параллельных текстов становится сильно меньше, чем в бытовой и разговорной тематике. Сочетание ухода в предметную область и не самого массового направления перевода приводит к слабым результатам. Скажем, IT. Казалось бы, какие сложности могут возникнуть у машинного перевода с текстом на тему информационных технологий? В самом деле — никаких, если мы занимаемся русско-английским переводом. Зато они тут же возникнут на русско-французской ниве! Статистическая база в этом направлении чрезвычайно скудная и лакуны возникают на каждом шагу. Выход в рамках СМ для подобных ситуаций найден лишь паллиативный: работая с языками / темами низкого покрытия в качестве посредника используется английский язык. То есть сперва делается перевод с русского на английский, а затем уже с английского на, скажем, румынский, или тайский. В результате получается очень заметное снижение качества перевода. Самое печальное, что проблема с плотностью покрытия в рамках СМ никак не решается принципиально. Единственный выход: нанять сотни тысяч переводчиков и заставить их заполнять лакуны по всем направлениям с низким статистическим покрытием. Как вы понимаете, никто это делать не сможет и не будет. Помимо сложностей с низкой плотностью переводов по направлениям, выпадающим из узкого мейнстрима, у СМ еще множество мелких изъянов. Например, статистическая модель совершенно убого справляется с переводами имен собственных. Многие помнят о переводе Ющенко, как Януковича, а России как Канады. Отрицание (частичка «не») — это очень сложное препятствие. Частичку «не» можно правильно позиционировать в результате лингвистического анализа текста, а СМ таковым не занимается. В результате предложения, содержащие отрицание, часто переводятся движками на статистической модели с точностью до наоборот. Как бы там ни было, ABBYY изначально отказалась от Rule Based Translation Model и замахнулась на систему компьютерного перевода нового поколения. Надо сказать, что придумывать особо ничего не требовалось. Универсальный язык понятий существует в структурной лингвистике в виде давней и несбыточной мечты еще со времен Людвига Витгенштейна. Даже Наум Хомский в своих ранних трудах лишь углублял существующую утопию. Проект Compreno исходил из трех основополагающих посылок: - использование качественного и бескомпромиссного синтаксического анализа. - создание универсальной когнитивной модели языка, возможность которой определяется аксиомой о том, что люди, хоть и живут в разных условиях и говорят на разных языках, однако в массе своей мыслят одинаково. Формы выражения мысли разные, а вот понятийный аппарат совпадает. - автоматизированное корпусное дообучение — лингвистические описания верифицируются и дополняются на основании статистической обработки корпусных данных. Исходя из этих посылок была сформулирована идея Универсальной Семантической Иерархии (УСИ), способной описывать явления от общего к частному. На составление этой иерархии у ABBYY и ушло 15 лет. Получилось то, что вы уже знаете: только на сегодняшний день 70 тысяч понятий в универсальной части когнитивной модели, более 80 тысяч — в русской, более 90 — в английской. Алгоритм машинного перевода, основанного на УСИ, выглядит следующим образом: - Лексический анализ текста (выделение слов, знаков препинания, цифр и прочих текстовых единиц); - Морфологический анализ (определение грамматических характеристик лексем); - Синтаксический анализ (установление структуры предложения); - Семантический анализ (выявление выражаемого значения в системе языка); - Синтез из универсальной семантической структуры предложения на выходном языке. В результате подбор слов для перевода осуществляется не напрямую из первого языка, а из понятийного набора, который, условно говоря, «висит» на той же ветке универсального семантического дерева, но только уже со стороны второго языка. Поскольку модель УСИ сквозная, нижестоящие элементы системы по иерархии наследуют признаки вышестоящих элементов. Это простое, казалось бы, обстоятельство позволяет добиваться беспрецедентной точности машинного перевода, поскольку каждое слово из переводимого предложения описывается максимальным набором понятийных эквивалентов, причем не только видового, но и родовых качеств на всех уровнях смысловой иерархии. В УСИ предусмотрены взаимосвязи между элементами структуры, относящимися к разным классам, и эти связи также структурированы и формализированы, что позволяет выполнять многоуровневый понятийный анализ текста, также повышающий качество перевода. В процессе создания УСИ разработчикам открылись неожиданные грани использования системы: помимо машинного перевода язык УСИ можно использовать в интеллектуальных смысловых поисках и, возможно, автоматическом распознавании речи на новом качественном уровне, который достигается за счет глубокой интеграции и взаимопроникновения синтаксиса и семантики в модели универсальной семантической иерархии. На альтернативных направлениях возникают, конечно, и свои сложности. Скажем, сегодня самым узким местом для глобального применения семантико-синтаксического анализа в массовых поисковых системах выступают очень высокие требования к компьютерным мощностям, необходимым для индексации информационных массивов на понятийном уровне. Требования эти несоизмеримо выше, чем при существующих формах традиционной индексации. Впрочем, уже сегодня методика семантико-синтаксического анализа может эффективно применяться (и применяется ABBYY — видел полностью функциональный прототип поискового движка собственными глазами) для более целенаправленного и узкого поиска в закрытых корпоративных системах. Мировых аналогов у Compreno сегодня нет, хотя в некоторых университетах и ведутся разработки в аналогичных направления. Однако фора в 15 лет, задействованные огромные человеческие ресурсы и материальные затраты позволяют надеяться, что ABBYY таки сумеет застолбить для себя эксклюзивное место первопроходца. На руку компании играет и то обстоятельство, что последние 10 лет подавляющая масса исследований в мире велась в русле статистической модели машинного перевода. За теоретическим введением в Compreno последовало более чем часовое погружение в демонстрацию работы движка компьютерного перевода, основанного на УСИ. Я сидел в одном из конференц-залов офиса ABBYY и непрестанно протирал глаза, все еще до конца не веря в услышанное и увиденного. 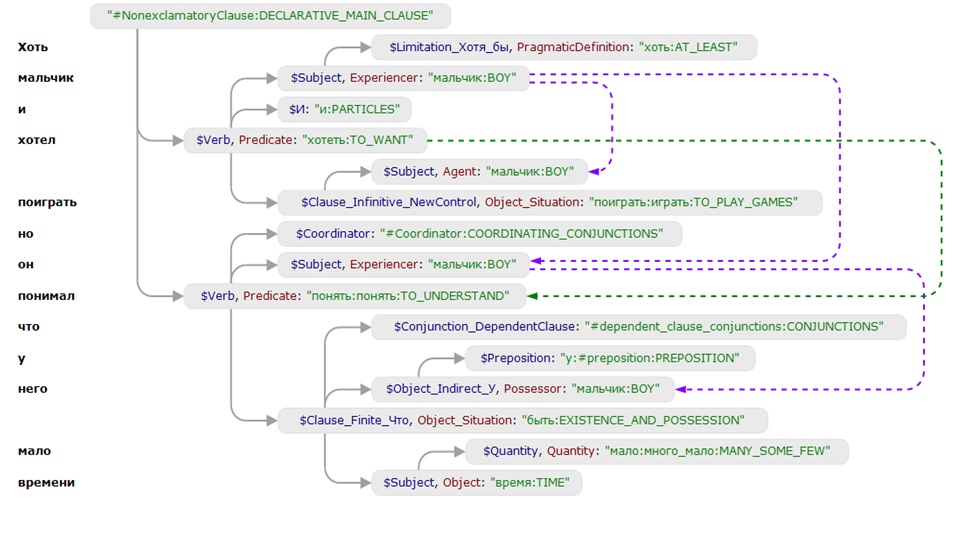   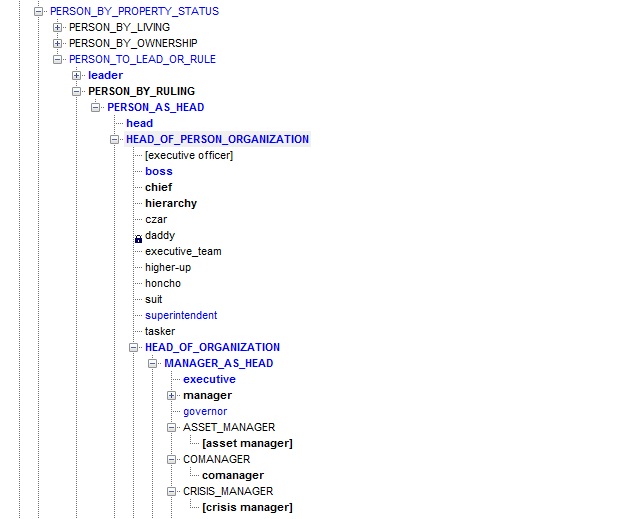 Теперь пользуюсь разрешением и демонстрирую читателям сравнение переводов, выданных Compreno и статистическим переводчиком (каким — гостеприимные хозяева просили не называть, но думаю, не маленькие и сами догадаетесь O Не сомневаюсь, что для любого человека, знающего толк в переводах, это сравнение откроет новую вселенную. Вот работа статистического переводчика (разумеется, предложения подобранны специально «поддых», поскольку бьют в самые слабые места статистической модели перевода). 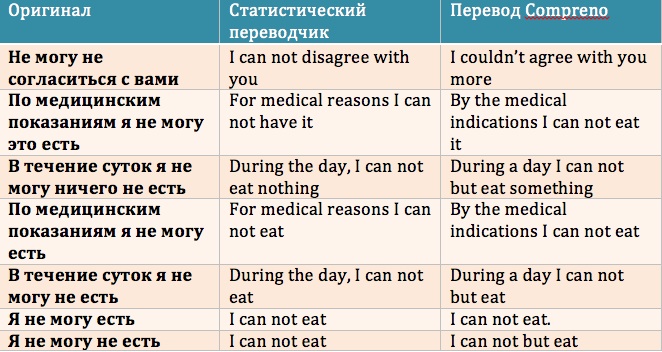 Это, господа, просто другой космос, другой уровень понимания текста. Это — революция! Смотрел я на это, слушал внимательно и, похоже, начал улавливать тайный смысл (шуточного) мотивационного плаката, висящего в одном из офисных коридоров ABBYY:  Примечания:Что показывают на Mobile World Congress 2012 Автор: Андрей Письменный КолумнистыКафедра Ваннаха: Экономика священных камней Автор: Михаил Ваннах Василий Щепетнёв: Место для рынка Автор: Василий Щепетнев Дмитрий Шабанов: Чудеса полового размножения Автор: Дмитрий Шабанов Кивино гнездо: Ключевые слабости Автор: Киви Берд Дмитрий Вибе: Я б в астрономы пошёл Автор: Дмитрий Вибе Голубятня-ОнлайнГолубятня: Чудо Compreno Автор: Сергей Голубицкий Version 1.0 -- document generated Компьютерра 27.02.2012 - 04.03.2012 >Статьи id="vision_0">Что показывают на Mobile World Congress 2012 Андрей Письменный Опубликовано 29 февраля 2012 года 
К выставке Mobile World Congress 2012, которая проходит в Барселоне, в HTC придержали три новые модели смартфонов на Android 4.0 Ice Cream Sandwich. Все они носят имя HTC One, различается лишь индекс: X, S и V. 
Главная новинка Samsung, показанная на барселонской выставке Mobile World Congress 2012 в Барселоне, — телефон со встроенным проектором под названием Galaxy beam. Представьте: достаточно включить проектор, направить устройство на чистую стену или даже потолок — и можно смотреть кино на аналоге пятидесятидюймового телевизора. 
Недавно мы писали о разрабатываемой в рамках проекта Mozilla мобильной платформе Boot2Gecko. Пользовательский интерфейс Boot2Gecko построен на основе того же браузерного движка, что и Firefox. Вчера на выставке Mobile World Congress в Барселоне было анонсировано первое устройство, использующее эту платформу. 
Компания SpareOne привезла на выставку Mobile World Congress в Барселоне свой единственный продукт — телефон, работающий от одной батарейки. Но зато как работающий! Одной батарейки хватает на несколько месяцев. 
На выставке Mobile World Congress 2012, которая проходит сейчас в Барселоне, компания Opera Software представила новые версии своих мобильных браузеров Opera Mobile и Opera Mini. 
ARLab — испано-израильская компания, специализирующаяся на дополненной реальности. На выставке Mobile World Congress в Барселоне компания демонстрирует, как при помощи фронтальной камеры iPad мобильное приложение способно распознать лицо человека, отслеживать его движения и накладывать поверх лица трёхмерное изображение. 

Что лучше, плохие новости или отсутствие новостей вообще? В Samsung решили быть честными до конца и на выставке Mobile World Congress, которая проходит сейчас в Барселоне, всё же признали: да, их планшеты продаются хуже, чем они ожидали. > Колумнисты id="own_0">Кафедра Ваннаха: Экономика священных камней Михаил Ваннах Опубликовано 27 февраля 2012 года Ах, какой уютной казалась Европа два десятилетия назад, особенно если смотреть на неё из России образца февраля 1992 года. Изобильные магазины, твёрдая валюта, чистые улицы, высокие зарплаты… Да и у тех, кто не мог или не хотел найти работу, всё было неплохо – высокие социальные выплаты, казалось, надёжно страховали европейцев от бедности… Прошло два десятилетия. Ну, репертуар в европейских магазинах всё ещё несопоставимо разнообразнее, нежели в отечественных, а цены – ниже. И улицы в Европе несопоставимо чище – нет там таких фокусов, как в типичном российском полумилионнике, где сокращают число дворников с 7000 до 1300 и пенсионерка может выйти на обледенелую улицу только в привезённых из Баварии горных башмаках на триконах. Но вот на экране бесятся «граждане греки, потомки великих людей» (как некогда писал Паустовский). Стотысячная толпа резвится в Афинах, поджигая дома и грабя магазины. Семь тысяч полицейских не в состоянии справиться с погромщиками – слезоточивый газ малоэффективен, даром что ли во Второй мировой химия не применялась. Но жалеть греков не стоит: даже сокращённая минимальная зарплата в этой стране составляет 560 евро в месяц (а средняя зарплата была где-то 2400 евро). Сравните с нашим Нечерноземьем, где климат куда строже. Но вот есть очень интересные цифры. Их любезно представляет нам Статистическое бюро Комиссии Европейских Сообществ (Евростат). Относятся эти цифры к такому явлению, как бедность. Которое, казалось бы, осталось где-то глубоко в прошлом, во всяком случае для того Золотого Миллиарда, о котором любят говорить отечественные публицисты. И цифры эти – довольно неожиданны. Вот что говорится в отчёте, опубликованном 8 февраля этого года. Оказывается, в 2010 году (масштабная статистика неизбежно запаздывает!) 115 миллионов счастливых европейцев, что составляет 23,4 процента населения ЕС, оказались перед риском бедности или вытеснения из социальной жизни. Это на 0,3 процента больше, чем в кризисном 2009 году. Риск бедности Евростат определяет как соответствие хотя бы одному из критериев: доходы ниже прожиточного минимума; нехватка денег на текущие платежи (скажем, коммунальные); низкая интенсивность труда в данном домохозяйстве. Хуже всего дела обстоят в Болгарии – там с проблемой бедности столкнулось 42 процента населения. Дальше – Румыния (41 процент), Латвия (38 процентов), Литва (33 процента) и Венгрия (30 процентов). Как видим, живо протестующей Греции среди этих стран нет, а доходы в Венгрии весьма скромны. Средняя зарплата 900 евро, ну а после уплаты налогов от неё остается около пяти сотен… Запомним пока эту цифру и обратимся к распределению бедности. Оказывается, самой подверженной ей категорией (несмотря на все игры в социальные государства) являются дети в возрасте до 18 лет – им бедность грозит в 27 процентах случаев. Ну а самой благополучной – граждане старше 64 лет, тут риску подвержен каждый пятый. Трудоспособные возраста – 23 процента. Так почему же призрак бедности (нет, бедности достаточно жирной, не сравнить ни с Африкой, ни с депрессивными регионами нашей страны) возник в благополучной Европе, весело заплясал на её «священных камнях»? Для ответа на этот вопрос обратимся к книге, с которой началась политэкономия. Это был «Treatise of taxes and contributions» – «Трактат о налогах и сборах». Вышла эта книга в свет в 1662-м году. И написал её Уильям Петти (1623-1687), личность весьма колоритная. Сын суконщика из Хэмпшира, в четырнадцать лет он поступает юнгой на флот. Списанный с переломом ноги поступает в Канский колледж во Франции – достаточное с точки зрения отцов-иезуитов знание латыни для этого он получил в местной школе своего родного городка. Ну а в колледже он постигает французский с греческим, математику и астрономию. В 1640 году Петти возвращается в Англию, живёт в Лондоне, зарабатывает на жизнь черчением морских карт. Обратим внимание: Петти работает в области информационного обеспечения флота, а он, и военный, Королевский, и торговый, был критически важен для тогдашней Англии, отнюдь ещё не правившей морями, но уже осознавшей важность морской торговли. Какое-то время Петти проводит в рядах Королевского Флота, потом возвращается на Континент, к учёбе. Изучает анатомию в Амстердаме и Париже, работает секретарем Томаса Гоббса, общается с блистательнейшими умами того времени — Гассенди, Декартом, Мерсенном… В 1646-м возвращается в Англию, где патентует копировальную машину (механическую, естественно, пантографическую, но весьма полезную при черчении карт) и учит медицину в Оксфорде. Вступает в Лондонское Философическое Общество и общается с Бойлем и, возможно, Мильтоном. В 1651 году Петти — профессор анатомии в Оксфорде и музыки в Лондоне. В 1652 году Петти отправляется с подавлявшей Ирландское восстание армией Кромвеля в Ирландию в качестве её главного медика. Там он опять займётся предпринимательством в доцифровой ИТ-области. Петти берёт в 1654 году подряд на картирование и межевание покорённой Ирландии. Эта работа была завершена в 1656-м и известна в истории как «The Down Survey». Петти заработал на ней гигантскую по тем временам сумму в 9000 фунтов стерлингов и стал собственником 120 кв. км ирландских земель. К этому было приложено и рыцарское звание сэра. Всё получено честным трудом (ну, если не считать того, что ирландцы были ограблены…). После Реставрации Петти продолжает трудиться на плодотворной ирландской ниве – он становится генеральным контролёром Ирландии и возводится в достоинство пэра Англии. (Оккупация англичанами Ирландии оплачивалась посредством конфискаций земель и экстраординарных налогов у самих ирландцев – понятно, что порядок тут был крайне важен.) Но интереса к науке он не теряет. Петти – член-учредитель Королевского общества. И из его «Трактата о налогах и сборах» через «Капитал» Маркса пришло к россиянам ставшее общеизвестным суждение: «Труд есть отец и активнейший принцип богатства, а земля — его мать». Ну, в земле Петти толк знал – недаром же так аккуратно и деловито отнимал её у жителей Эйре. Ну и с трудом всё понятно. Бездельником-то Петти никак не назовёшь. (И в утешение ирландцам: он помог под конец жизни организовать Дублинское общество…) Так вот, возьмём и посмотрим, как у нынешних европейцев обстоят дела с трудом. На ком мы остановились, на Венгрии? Ну, вот что нам любезно сообщает «Компьюлента»: 2300 работников будут сокращены с заводов Nokia в этой стране. Рабочие места перетекают в Юго-Восточную Азию. Сколько получали мадьяры на Nokia, найти не удалось, но давайте в первом приближении плясать от средней зарплаты в 900 евро. А вот соседнее предприятие в Нечерноземье. Оно предлагает радиомонтажницам зарплату в 35 тысяч рублей в месяц. (Это – пошли в российскую оборонку 20 триллионов.) Налоги у нас поменьше, так что «чистыми» останется побольше, чем остающиеся у венгров со средней зарплаты 500 евро. (Но в Нечерноземье и еда, и тряпки, и даже недвижимость подороже будапештских будут…) Но для Nokia труд европейцев по таким тарифам слишком дорог. Азиаты – дешевле. И на логистике можно сэкономить – комплектующие-то нынче тоже производятся у тёплых морей. И экономят в Nokia не только на венграх, но и на самих жителях Суоми — 1000 финнов потеряет на её заводах работу. Так что это дополнительный вклад в численность европейцев с низкой интенсивностью труда. И пастор родственной церкви из старинного голландского городка пишет, что японцы закрывают у них завод – 1600 человек прямых сокращений, но есть же и мелкие фирмы, которые поставляли на завод компьютеры, бухгалтерские (по местному законодательству и стандартам) пакеты, монтировали и обслуживали информационные сети, готовили и привозили еду в столовую, мыли полы и тротуары… Складывается социальная ситуация, которую европейцы в возрасте «за шестьдесят» никогда не видели. И формирует эту ситуацию не политика, а технология. Делающая ненужными многие виды труда. Ну, давно ли вы, уважаемые читатели, пользовались бумажной газетой? Пресса прочно ассоциируется нынче с экраном планшета, ноутбука на кухонном столе или наладонника. Нет, бумажные газеты, конечно, тоже нужны. Рекламные издания, привезённые в багажнике из ближайшего бизнес-центра, вполне пригодны для того, чтобы во время ремонта накидать их на лестничную клетку, дабы они впитали растекающуюся побелку… (Бригада молодёжная, и не гастарбайтерская – два юриста и два экономиста, столкнувшиеся с реальностью рынка труда…) Из сферы информационного оборота бумага и многочисленные связанные с нею профессии уходят. Как бы ни было жаль свежего журнала, пахнущего типографской краской, но это – навсегда. (Хм, запатентовать, что-ли, идею читалок и планшетов, в начале чтения нового файла испускающих запах краски, слабеющий по мере чтения…) Слишком долго тащится к читателю бумага. Слишком большие издержки с этим связаны. Да и реклама удобнее в электронном виде. На редкие товары вам услужливо подсунет её поисковик. В случае популярной продукции с высокой маржей (скажем, квартир) вам придётся пробиваться через информационный шум, но это задача решаемая, а из рекламных газет привлекательные объявления будут, скорее всего, полностью изъяты посредниками, и вы с ними не встретитесь никак. Но это – другой разговор. А вот нарастание бедности в благополучной Европе – факт. Связанный, прежде всего, с уходом из неё индустриального труда. (Скажем, в социалистической Болгарии доля индустрии в ВВП была почти половинной, а сейчас – чуть больше четверти…) И от процессов этих мы не застрахованы. Вот, при сравнимых с оборонно-нечернозёмными зарплатах, Nokia завод-то закрыла. Да, у нас, в отличие от Европы, есть ещё и земля. И земля сельхозназначения (российское зерно опять рентабельно на мировом рынке), и, главное, горные богатства, лежащие под ней. Именно на ней, на горной ренте, основан российский экономический рост начала двадцать первого века. И приличные зарплаты монтажницам радиоаппаратуры обусловлены тем, что землю эту надо защищать — надо суметь удержать её в руках. Но на процессы в Европе надо смотреть внимательно. И потому, что Европа – крупнейший покупатель российских углеводородов. И потому, что судьба европейской индустрии даёт нам очень жестокий урок, который, возможно, есть смысл выучить… id="own_1"> Василий Щепетнёв: Место для рынка Василий Щепетнев Опубликовано 28 февраля 2012 года Общественные науки в медицинском институте доминировали над остальными. Часов, отведённых на изучение истории партии, политической экономики, диалектического материализма, материализма исторического, научного коммунизма и научного атеизма, в сумме было намного больше, нежели отведённых на дерматовенерологию или на глазные болезни. Да что в сумме, и по отдельности больше. Сидишь вечером в библиотеке, конспектируешь «Три источника и три составные части марксизма», а сам думаешь, что в работе врача это не пригодится. Вряд ли. Но преподаватели общественных наук говорили: для страны важнее, чтобы человек из института вышел пусть и не хватающим звёзд с медицинского неба доктором, зато убеждённым борцом за дело коммунизма, нежели беспринципным специалистом с гнилой буржуазной сердцевиной. Однако концы с концами не сходились. О марксистко-ленинском учении можно говорить всякое, но уж чему-чему, а жизни в нерассуждении оно не учит. Возьмите любою работу основоположников. Где тут робость и покорность? Напротив, бунт, и бунт разумный. Со смыслом. Человек, владеющий азами диалектики, уже не проглотит молча любой бред и не будет тянуть руку, голосуя единогласно за «бред кобылы сивой, одна штука». И в то же время в институте от нас требовали жить именно в нерассуждении, тянуть руку вверх единогласно по команде. То ж и после института. То есть о футболе рассуждать дозволялось, если рассуждения патриотические, а вот о системе оплаты за труд – ни-ни. Размышлять же вслух о возможности выбирать руководителя страны считалось верным признаком шизофрении. Сидел я в минуту затишья на неудобном диване (к ставке дерматовенеролога больницы в райцентре Тёплое я брал сотню часов дежурствами с дислокацией в избушке «скорой помощи») и думал: в чём, собственно, выражается создаваемая мной прибавочная стоимость? Вот полчаса назад я освидетельствовал водителя, совершившего ДТП. Заполнил акт и отдал капитану милиции. Что ж, этот акт и есть стоимости? А час назад привезли парня с ущемлённой грыжей. Я вызвал хирургов, которые сейчас оперируют больного. Где в моём действии стоимость, простая и прибавочная? А ведь должна быть, иначе за что же я получаю зарплату? Потихоньку продолжил: ага, я обслуживаю в первую очередь гегемон. Рабочий класс и социалистическое крестьянство. Привожу его в порядок по мере собственных способностей, доступности медикаментов и прочих лечебных факторов и всеобщего развития медицинской науки. А уж он-то, гегемон, и производит настоящую стоимость. Значит, в его труде есть и мой, но только капелька. Из этих капелек и складывается оклад врача-дерматовенеролога, сто двадцать пять рублей в сельской местности и сто десять в городской. Минус налоги. Мало? Тогда либо бери подработку, либо иди к станку. Решив таким образом насущные вопросы, я шёл далее: поскольку оклад есть штука постоянная, то чем меньше человек работает, тем эффективнее его труд, не так ли? То есть если я работал много и – условно – вылечил за месяц пятьсот человек, то стоимость излечения одной души (в помещичье-крепостном смысле) составляет двадцать пять копеек. Если же я вылечу только сто человек, то стоимость излечения души составит рубль двадцать пять. А если вылечу всего десять человек? Эге! Это получится двенадцать с полтиной, оплата всей коммуналки. А если, предположим, я вообще никого не вылечу? Делим сто двадцать пять на ноль и получаем… получаем… Здесь меня спас коллега-хирург, пришедший после операции узнать, нет ли ещё какой работы: мол, не ломай голову, платят нам вовсе не за лечение людей, а за проведённые на рабочем месте часы. То есть государство в лице центральной районной больницы покупает время нашей жизни. А мы его, время, продаём. По расценкам обыкновенным, вот как я, или по расценкам сверхурочным, вот как он сейчас, оперируя с полуночи до трёх. Потому что больше нам, пролетариям от медицины, продавать нечего. И он ушёл досыпать остаток ночи, фельдшер с водителем поехали в дальнюю деревню на вызов «понос у ребёнка пятый день, терпели, терпели, а толку нет», а я остался в избушке. Можно было и подремать, но не дремалось. На полочке лежала книжка в мягкой обложке белого цвета. Ленин, «Империализм как высшая стадия капитализма». Говорят, прежний водитель когда-то учился в заочном техникуме – и тоже конспектировал. Закончив учёбу, он перешёл в «Сельхозтехнику» на полуответственную должность, оставив книжку, похожую на парус надежды, в назидание другим: ученье – свет! И я стал читать про империализм. Рынки сбыта, рынки сырья… Из-за них и войны. Должен же капитализм кому-нибудь продавать присвоенную прибавочную стоимость. А кому? Поскольку трудящиеся денег за неё не получают по определению, кто ж её купит в своей стране? Внешние рынки и выручают. Поскольку же внешних рынков не так и много, идёт борьба за их передел. Порой она, борьба, проявляется в виде империалистической войны. Я читал, но было немного странно. В начале восьмидесятых любой импортный товар, хоть обувь, хоть крем для бритья, хоть даже носки, доставать нужно было с боем. Или по знакомству. Импортный – это польский, венгерский, болгарский… Изделия из стран империалистических в розничной торговле не встречались, а приобретались с рук по ценам, казавшимся астрономическими: штаны – две месячные зарплаты врача, магнитофон – трёхгодовая зарплата, на компьютер IBM PC нужно было работать всю жизнь (я о цене знал от товарища, у которого знакомый видел человека, который ходил в гости к сыну члена Политбюро, у которого такой компьютер был). Значит, завоевать рынок желаете? Наш? Хм… С одной стороны, это очень плохо, а с другой… Нужно же чем-то бриться и в чём-то ходить? Борьба за рынки – понимаю. Наша страна и Асуанскую плотину построила, перебив контракт у буржуев, и всякие трактора, сеялки и комбайны назло Западу поставляет африканским братьям в долг, то есть даром: даже и сельскому врачу было совершенно ясно, что никогда Эфиопия и прочие мозамбики расплачиваться за поставки не станут. Не понимаю, почему нет лезвий для бритья, мыла и батареек для фонарика. Советскими лезвиями «Спутник» не пользовались даже в посёлке Тёплое, уж больно кроваво выходило. Или на фабриках тоже почасовая оплата? Государству и здесь нужно время человека, а лезвия, мыло и батарейки – дело десятое? Но если… Но если случится немыслимое и капитализм победит во всём мире? Победит, захватит рынки до единого? Дальше, дальше-то что? Если весь-весь мир станет Огромной Империей Зла, где она, Империя, найдёт рынок сбыта? И тут то ли от переутомления, то ли по иной причине, но меня осенило: рынки не вовне, не в пространстве! Рынки в головах! Те же компьютеры: не было прежде никакого рынка компьютеров, а теперь появился. Или дезодоранты: жили веками без дезодорантов. Мылись, тем и довольствовались, а ныне – шалишь. Капитализм будет изобретать новые и новые потребности, навязывать их массам, тем и спасётся. В избушке я был один, и потому крамольную мысль о спасении капитализма произнёс вслух. Или мог произнести, что, в сущности, одно и то же. Война будет идти, уже идёт не за внешние рынки, а за умы потребителей. Заставил потребителя купить что-нибудь такое, чего он раньше никогда не покупал, – тем победил. И я тут же записал ночные мысли тезисно. Карандашом на внутренней стороне обложки работы Ленина. А сырьевые рынки? Нефть, газ, руда, пушнина, лягушки (упорно ходили слухи, что где-то поблизости выращивают лягушек и продают во Францию за валюту)? Ну, во-первых, сырьё возьмёт на себя функцию денег, что и снимет проблему «чем расплачиваться за прибавленную стоимость». А во-вторых (тут меня опять осенило), сырьём могут стать те же умы! Скупать будут умных на корню, таких, которые сразу или же после предварительной обработки смогут придумывать новые процессы, которые воплотятся в новые товары, которые будут завоевывать новые рынки (усталость давала-таки о себе знать, и косноязычие всё больше овладевало мной). Потом, оглянувшись на всякий случай, я спрятал книгу в портфель. Никто её и не хватился, а то б я вернул, я бы непременно вернул! Отработав до восьми на дежурстве и, без перерыва, до трёх на приёме, я пришёл домой. Понимая, что далеко не Ленин, раз, и далеко не в Швейцарии, два, я переложил книгу с тезисами в коробку «неоконченного», где она и лежала до недавнего времени вместе с повестью о жизни Вересаева, прерванной на восьмой странице, переделкой беляевского романа «Человек-Амфибия» и прочими дерзаниями молодости. id="own_2"> Дмитрий Шабанов: Чудеса полового размножения Дмитрий Шабанов Опубликовано 29 февраля 2012 года Обсуждение последних «эволюционных» колонок привлекло внимание к теме эволюции эволюции. Некоторым читателям сложно поверить, что разные группы организмов эволюционируют (вырабатывают приспособления) по-разному. Я приведу примеры из области своей работы. Из эволюционных приобретений, ускоряющих эволюцию, самыми крупными мне кажутся половое размножение и культурное наследование. О культурном наследовании мы говорили. Успехи нашего вида — свидетельство мощи этого способа выработки приспособлений. Намного более давнее изобретение — пол, точнее — гапло-диплоидный жизненный цикл с мейозом. Сейчас объясню, что это значит. Обмен генетической информацией несравнимо ускоряет эволюцию организмов с половым размножением по сравнению с бесполыми видами (может, как-нибудь сделаю модель и обосную это утверждение на её примере). Но получение генетической информации «со стороны» требует особого жизненного цикла. Представьте: клетка с определённым набором хромосом (молекулярных комплексов, несущих генетическую информацию) раз за разом принимает новые. Как уменьшить избыточный хромосомный запас? Проще всего эта проблема решается при парасексуальном процессе. Он характерен для многих грибов, таких, как пеницилл или аспергилл — плесеней на наших кухнях. Гифы (нитевидные грибные тела) разных генетических индивидов соприкасаются и передают друг другу ядра. Разные ядра могут сливаться, образуя гибридные ядра с двойным набором хромосом. Эти ядра, как и остальные, делятся надвое в процессе, который называется митозом. Митоз — самое распространённое деление ядер и клеток; наши тела тоже образуются благодаря этому способу деления. При митозах гибридных ядер у грибов в них шаг за шагом происходит элиминация (удаление) избыточных хромосом. Иногда при этом наблюдается рекомбинация — обмен участками между парными хромосомами, образование новых сочетаний генетического материала. Разные ядра, образовавшиеся после упрощения гибридного ядра, имеют разные по происхождению части хромосом. 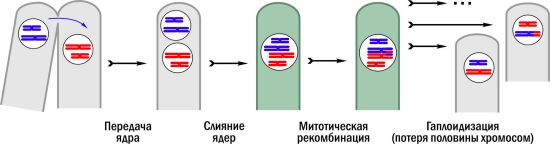
На рисунке гифы, где ядра имеют гаплоидный (единичный) набор хромосом, показаны серым, а диплоидные (с двумя хромосомными наборами) окрашены зеленоватым. Впрочем, жизнь сложнее схемы. Диплоидные ядра грибов становятся гаплоидными постепенно, после многих митозов, а в одних и тех же гифах могут находиться различные ядра. Большей сложности добились организмы, у которых для сокращения хромосомного набора используется особый тип деления — мейоз. Сравнение митоза и мейоза показано на схеме (не пугайтесь: это стандартный школьный материал!). Мейоз состоит из двух последовательных делений. В первом между дочерними клетками расходятся хромосомы, во втором, как и при митозе, хромосомы расщепляются на хроматиды. В результате получаются четыре генетически уникальные клетки. 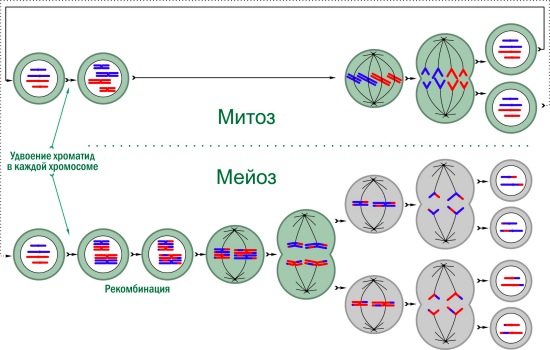 Сравнение митоза и мейоза. Митоз — цикл; некоторые из образующихся в нём клеток могут переходить к мейозу. Хромосомы могут состоять из одной хроматиды или, после удвоения генетического материала, из двух. Гаплоидные клетки серые, диплоидные — зеленоватые
Сравнение митоза и мейоза. Митоз — цикл; некоторые из образующихся в нём клеток могут переходить к мейозу. Хромосомы могут состоять из одной хроматиды или, после удвоения генетического материала, из двух. Гаплоидные клетки серые, диплоидные — зеленоватые
Благодаря мейозу постоянной частью жизненного цикла может стать оплодотворение: слияние гамет (половых клеток) образует зиготу. Оплодотворение увеличивает хромосомный набор вдвое, а мейоз — сокращает. 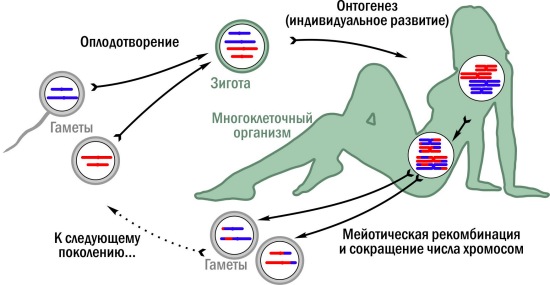 Типичный гапло-диплоидный жизненный цикл с мейозом. Гаплоидные стадии серые, диплоидные — зеленоватые
Типичный гапло-диплоидный жизненный цикл с мейозом. Гаплоидные стадии серые, диплоидные — зеленоватые
На схеме показан жизненный цикл, в котором многоклеточный организм развивается на диплоидной фазе. Это не единственное возможное решение. У некоторых архаичных видов многоклеточные стадии жизненного цикла гаплоидны, а мейоз происходит сразу после оплодотворения. Для растений типичны циклы, где многоклеточные организмы возникают и на диплоидной, и на гаплоидной фазах. В любом случае гапло-диплоидный жизненный цикл с мейозом (теперь вы поняли, что это означает) — это эволюционный мейнстрим. Но после его возникновения эксперименты со способами размножения не прекратились. Начну с примера, который мне близок. Я занимаюсь изучением гибридизации зелёных лягушек (подробнее — здесь). Не вдаваясь в детали, скажу, что два разных вида зелёных лягушек скрещиваются, порождая гибриды (Pelophylax esculentus). У диплоидных гибридов до мейоза в тех клетках, из которых образуются гаметы, элиминируется один родительский хромосомный набор. Тут есть некая аналогия с элиминацией хромосом при парасексуальном процессе у грибов, но у грибов может быть удалена любая хромосома в каждой паре, а лягушки теряют один набор целиком. Затем в клетках, которые стали гаплоидными, хромосомный набор удваивается при эндомитозе («внутреннем» митозе, удвоением хромосом без деления). Получается диплоидная клетка с двумя идентичными хромосомными наборами. Между ними происходит рекомбинация, которая в типичном случае ничего не меняет: одинаковые хромосомы обмениваются идентичными участками. В результате получаются гаметы, несущие хромосомный набор одного из родительских видов без изменений, клонально. Поскольку клонально передаётся лишь один геном, такое размножение называется полуклональным (гемиклональным). Кроме зелёных лягушек, оно найдено ещё в некоторых группах животных. 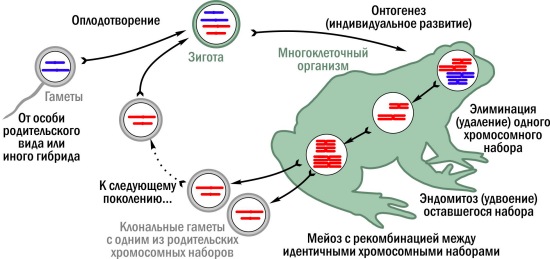 Полуклональное наследование у межвидовых гибридов зелёных лягушек. Цвет хромосом тут показывает их принадлежность к разным видам
Полуклональное наследование у межвидовых гибридов зелёных лягушек. Цвет хромосом тут показывает их принадлежность к разным видам
Обратите внимание: у полуклональных зелёных лягушек меняется сам механизм передачи наследственной информации между поколениями. Следствием этого является особый способ их эволюционирования! Теперь настало время сообщить, что в некоторых регионах обитания гибридных лягушек (например, там, где я работаю) кроме диплоидных особей есть ещё и триплоидные — с тремя хромосомными наборами. Не так давно азбучной истиной считалось, что триплоидные животные не способны к половому размножению: их хромосомы не могут объединиться попарно во время мейоза. Но триплоидные лягушки нашли уловки, позволяющие обойти это ограничение. Здесь я опишу тот вариант, который можно считать типичным. В отличие от двух предыдущих рисунков, я не буду рисовать полный цикл воспроизводства триплоидов. Он изучен для Западной Европы и отличается там в разных регионах; мы ещё толком не установили механизмы возникновения триплоидов в районе нашей работы, но знаем, какие гаметы они производят чаще всего. 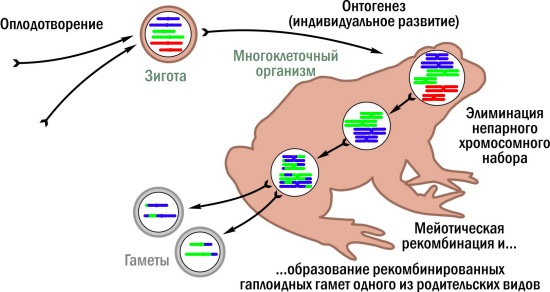 "Типичное" образование гамет у триплоидных лягушек. Красные хромосомы принадлежат одному родительскому виду, синие и зелёные — другому. Триплоидные стадии — красноватые
"Типичное" образование гамет у триплоидных лягушек. Красные хромосомы принадлежат одному родительскому виду, синие и зелёные — другому. Триплоидные стадии — красноватые
Всего лишь отказавшись от эндомитоза (удвоения оставшихся наборов), триплоидные лягушки могут производить гаплоидные гаметы, причём не клональные, а рекомбинированные — такие, какие производили бы представители родительских видов. А если эндомитоз всё-таки произойдёт, гаметы должны стать диплоидными. Если при оплодотворении сольются диплоидная и гаплоидная гаметы, возникнет новый триплоид. Существование триплоидных лягушек кажется вам курьёзом? Не торопитесь. Одна из выгод, с которой связано половое размножение, — именно рекомбинация, непрерывная пересортировка генов, позволяющая избавляться от неблагоприятных мутаций. Клонально передающиеся хромосомы накапливают аномалии и постепенно теряют жизнеспособность. Это, например, происходит у диплоидных полуклональных лягушек. В нашем регионе, в бассейне реки Северский Донец, отсутствует один из родительских видов гибридных лягушек, Pelophylax lessonae. Все его хромосомные наборы передаются через гибридов, но при этом не дегенерируют. Видимо, это следствие того, что они подвергаются рекомбинации у триплоидов. Благодаря триплоидам возникает новое качество эволюции гибридов, способных обходиться без родительских видов! В моём рассказе остался последний шаг. В конце XX века немецкий батрахолог (специалист по изучению амфибий) Маттиас Штёк начал серию экстремальных путешествий по Центральной Азии. Он был там, откуда для европейца вернуться живым — большая удача. В 1999 году Штёк и его коллеги описали первый триплоидный вид позвоночных, состоящий из нормально скрещивающихся самцов и самок. Это жабы Bufo baturae, найденные в засушливых высокогорьях Каракорума в Пакистане. В прошлом году опубликованы результаты тщательных исследований размножения этих жаб. Если интересно, неформальный перевод статьи Штёка и его соавторов выложен на моём сайте.  Поющий самец пуштунской жабы и пара жаб на нересте (видите шнуры икры?). Фото М. Штёка
Поющий самец пуштунской жабы и пара жаб на нересте (видите шнуры икры?). Фото М. Штёка
Сложный вопрос: как назвать Bufo baturae по-русски? Во время написания этой колонки я посоветовался с безусловным авторитетом — Спартаком Литвинчуком из Петербурга (спасибо ему за консультацию!). Он сказал, что неформально он и его коллеги называют этот вид пуштунской жабой. Что ж, и я использую это название — неофициально. Пуштунская жаба — вид гибридного происхождения. От одного родительского вида она унаследовала один хромосомный набор, лишённый ядрышкового организатора, от другого — два набора с ядрышковыми организаторами. Не вдаваясь в детали, скажу, что ядрышковый организатор — зона на определённых хромосомах, видимая при специфичном окрашивании. Примем условно, что у пуштунских жаб есть один "-"-набор хромосом и два "+"-набора. Образование гамет у самок и самцов пуштунских жаб идёт по-разному. Самцы реализуют вариант, описанный выше для триплоидных лягушек: "-"-набор элиминируется, а два "+"-набора проходят через обычный мейоз. На выходе — гаплоидные сперматозоиды с одним рекомбинантным "+"-набором. У самок перед образованием гамет "-"-набор удваивается, и получаются клетки с четырьмя наборами: два "-" и два "+". Проходит нормальный мейоз. У "-"-наборов рекомбинация идёт между идентичными копиями и ничего не меняет, а у "+"-наборов рекомбинация порождает новые сочетания хромосомного материала. Самки производят диплоидные яйцеклетки с одним "-"-набором и одним "+"-набором. При оплодотворении "+"-сперматозоидом восстанавливается исходная генетическая конструкция. 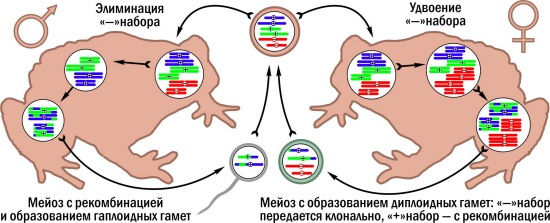 Размножение пуштунских жаб Bufo baturae. Унаследованный от одного вида-родителя "-"-набор (красный) передаётся клонально, "+"-наборы от другого вида — рекомбинантно
Размножение пуштунских жаб Bufo baturae. Унаследованный от одного вида-родителя "-"-набор (красный) передаётся клонально, "+"-наборы от другого вида — рекомбинантно
Более всего меня удивляет то, что из комплекта в 33 хромосомы у самок пуштунских жаб перед мейозом удваиваются только те 11, которые принадлежат к "-"-набору. Как такое может быть — 11 хромосом удваиваются, а ещё 22 просто находятся в том же ядре? Мне проще поверить, что удваиваются все хромосомы, но потом лишние копии "+"-наборов элиминируются. Так или иначе, пуштунская жаба обходится со своим генетическим материалом иначе, чем большинство обитателей этой планеты. Штёк и соавторы считают, что "-"-набор пуштунской жабы должен дегенерировать вследствие клональной передачи. Они считают, что этот вид возник совсем недавно и обречён на вымирание. У меня этот прогноз вызывает сомнение. Вспомните: гибридные зелёные лягушки нашли способ «омоложения» своих клональных наборов в триплоидных особях. Я допускаю, что и у пуштунских жаб временами случается что-то подобное. Для меня очевидно, что особенности эволюции, способы выработки приспособлений, механизмы передачи и изменения генов — разные у бесполых видов, парасексуального пеницилла, людей и других животных с типичным половым циклом, полуклональных зелёных лягушек и совсем уж невероятных пуштунских жаб. И не думайте, что неожиданности, на которые можно наткнуться при изучении способов размножения разных видов, исчерпаны! Кстати, пуштунская жаба уже не одинока. Мои коллеги из Санкт-Петербурга нашли подобный вид на Памире, а в прошлом году — ещё один в Западных Трансгималаях. Подождём, что станет известно о способах размножения новых находок... id="own_3"> Кивино гнездо: Ключевые слабости Киви Берд Опубликовано 01 марта 2012 года В августе нынешнего года в калифорнийском городке Санта-Барбара пройдёт международная криптографическая конференция CRYPTO 2012, дающая своего рода срез текущего состояния дел в этой области прикладной математики. И хотя до начала мероприятия остаётся ещё полгода, уже сегодня можно с уверенностью сказать, какая из тем обсуждения будет среди самых горячих. Прогнозировать это несложно, потому что одна из исследовательских работ, намеченных для доклада на CRYPTO, опубликована уже сейчас и сразу же вызвала заметный резонанс. Ибо то, что исследователям – команде криптографов из Европы и США – удалось обнаружить, для большинства специалистов от академической науки оказалось, выражаясь поделикатнее, сильной неожиданностью. Для начала имеет смысл подоходчивее объяснить, что же за результаты удалось получить команде исследователей, которую возглавляли известный голландский математик-криптограф Арьен Ленстра (Arjen K. Lenstra) и независимый калифорнийский криптоэксперт Джеймс Хьюз (James P. Hughes). В настоящее время Ленстра является профессором Лозаннского федерального политехникума (Ecole Polytechnique Federale de Lausanne), так что все остальные криптографы — соавторы этой большой работы также представляют данный швейцарский вуз. Целью исследования, занявшего в общей сложности около трёх лет, являлся тщательный аналитический обзор той необъятной массы криптоключей, что повсеместно применяются ныне в реальной жизни. То есть учёные кропотливо собрали из интернет-баз все те ключи и сертификаты, что по определению предполагаются общедоступными и составляют основу криптографии с открытым ключом. Криптосхемы такого рода, обеспечивающие засекреченную связь для совершенно незнакомых и никогда прежде не общавшихся сторон, ныне повсеместно используются по всему миру для онлайновых покупок, в банковских операциях, для защиты электронной почты и всех прочих интернет-сервисов, подразумевающих защиту информации и приватности пользователей. И именно здесь при тщательном анализе ключей удалось обнаружить неожиданную и весьма серьёзную слабость, присущую практически всем криптосистемам такого рода, но в первую очередь RSA – как в силу конструктивных особенностей этого алгоритма, так и по причине его популярности. Именно RSA используется для генерации сертификатов протокола SSL, повсеместно применяемого для шифрования соединений в интернете. Для того чтобы вся эта система работала, лежащий в основе стойкости RSA ключевой элемент под названием «модуль» должен быть произведением двух очень больших простых чисел, причём для каждого конкретного ключа эти числа должны быть строго уникальными. Выходит, что стойкость криптографии с открытым ключом составляет не 100процентов, а лишь 99,6. Казалось бы, не такой уж плохой результат для реальной защиты информации. Но аналитики оценивают этот итог существенно иначе. Потому что, согласно теоретическим расчётам, 0,4 процента никудышных ключей не должны были появиться. По свидетельству Хьюза, в тех случаях, когда генерация ключей делается правильно, для случайного числа-ключа длиной 1024 бита теоретически понадобилось бы сгенерировать ещё 2200 других ключей, прежде чем будут исчерпаны прочие множители-факторы и появится повторение. Гигантское количество 2200, для сравнения и примерного представления о его размерах, можно иначе (приближённо) записать как 1060. Если же для каждого из семи миллиардов жителей планеты ежесекундно вырабатывать по одному такому ключу, то даже за сто лет общее число сгенерированных ключей будет измеряться числом с шестнадцатью нулями. А здесь этих нулей шестьдесят. Это странно с математической точки зрения, но в действительности дело обстоит, похоже, даже круче. Хотя основная масса всех аналитических усилий команды была сосредоточена на (общераспространённых ныне) ключах длиной 1024 бита, в поле их зрения попадали и более длинные 2048-разрядные ключи. И хотя в теории столь огромные числа должны предоставлять просто-таки невообразимо гигантское пространство энтропии, напрочь исключающее возможности повторения множителей, многочисленные ключи с общими факторами выявлены и здесь. Но и это ещё не всё. Аналогичные нынешним исследования проводились и ранее, правда, на меньшем количестве ключей. Исследованный ныне массив из семи миллионов – это тоже далеко не все применяемые в мире ключи. Очень важным новым открытием стал такой факт: процентная доля ключей, для которых установлено, что они сгенерированы с помощью неуникальных множителей, скорее всего, будет возрастать и далее по мере того, как будут становиться доступными для анализа ещё большие количества ключей. Доля 0,4 (точнее — 0,38) процента дефективных ключей была обнаружена в условиях, когда исследователи просмотрели в общей сложности 7,1 миллиона ключей, в то время как выявленная в более раннем исследовании доля дефективных ключей в размере 0,26 процента соответствовала проанализированному числу из 4,7 миллиона модулей RSA. Иначе говоря, как результат такой зависимости, подлинное количество ключей, которые на самом деле можно было бы вскрыть, используя данный подход, может оказаться даже выше, чем показывает нынешнее исследование. Пытаясь логически осмыслить полученные результаты, учёные пришли к выводу, что кто-то наверняка уже знает об этом. Непосредственно в их статье данная мысль сформулирована следующим образом: «Учитывая отсутствие в наших методах анализа каких-то хитрых и сложных приёмов, а также последовавшие за этим открытия, очень трудно поверить, будто представленная нами работа является чем-то совершенно новым. Особенно принимая во внимание, что существуют организации, известные обострённым любопытством к подобного рода делам». Комментируя эти выводы в своем блоге, известный криптоэксперт Брюс Шнайер особо отмечает, что главной причиной выявленной слабости практически наверняка является некачественный генератор случайных чисел, применявшийся для создания этих открытых ключей. И это не должно никого удивлять. Одна из самых трудных частей криптографии, напоминает эксперт, — это качественная генерация случайных чисел. При этом низкое качество генератора случайных чисел может быть совершенно неочевидным на первый взгляд. Так что нельзя исключать, что слабые ключи появляются как результат слабого понимания криптографии и случайных неблагоприятных обстоятельств. Один из репортёров, сообщивших Шнайеру об этой истории, попутно поделился с ним сплетней: будто сами исследователи ему рассказали о совершенно реальном генераторе случайных чисел из применяемого в жизни криптоприложения, на выходе которого выдавалось всего семь разных случайных чисел. Но с другой стороны, отмечает Шнайер, нельзя исключать и другой вариант: некоторые генераторы случайных чисел могли быть ослаблены умышленно. Очевидным подозреваемым тут будут государственные разведслужбы вроде АНБ США. На всякий случай эксперт тут же оговаривается, что у него нет никаких свидетельств тому, что подобное действительно случалось. Однако, продолжает Шнайер, если бы он сам отвечал за ослабление криптосистем в реальном мире (чем спецслужбы вроде АНБ заведомо известны), то первая вещь, на которую он бы нацелился, стали бы именно генераторы случайных чисел. Их легко ослабить, а заметить слабость — довольно трудно. Это намного безопаснее, чем шаманить с алгоритмами, которые можно протестировать с помощью уже известных контрольных примеров и альтернативных реализаций. Но, ещё раз оговаривается Шнайер, всё это лишь фантазии информированного человека... Возвращаясь к тексту исследовательской работы Ленстры и его коллег, нельзя не отметить и такой факт: хотя сами учёные назвали свои методы анализа простыми и незамысловатыми, непосредственно оценить это невозможно. Потому что конкретный способ, применявшийся ими для выявления ключей, сгенерированных неуникальными множителями, в самой статье не описывается. Как не указаны и списки скомпрометированных сертификатов или держателей слабых ключей. Со слов одного из участников, Джеймса Хьюза, известно лишь то, что их команда нашла вычислительно эффективный способ для «помечивания» ключей – без необходимости индивидуального сравнения каждого нового со всеми предыдущими. Другой главный участник работы, Арьен Ленстра, счёл необходимым прокомментировать в интервью для прессы, почему они решили опубликовать свои открытия уже сейчас – существенно раньше начала августовской конференции. Таким образом, по свидетельству Ленстры, исследователи хотели бы как можно раньше предупредить всех пользователей криптографии с открытым ключом о выявлении столь большого количества слабых модулей. Хотя их команде на проведение этого исследования потребовалось три года, они полагают, что грамотным коллегам хватит нескольких недель на воспроизведение тех же результатов по уже известному в общих чертах рецепту. Попутно, правда, это важное открытие подняло и весьма непростой вопрос о том, каким образом раскрыть подобного рода информацию, не облегчая при этом для злоумышленников взлом десятков тысяч скомпрометированных ключей. Цитируем работу: «То гигантское количество уязвимых ключей, с которым мы столкнулись, делает непосильным правильное информирование всех и каждого, кто непосредственно с этим связан, хотя мы и предприняли всё для нас возможное для информирования наиболее крупных сторон, разослав также письма по всем тем email-адресам, которые были указаны в валидных сертификатах. Наше решение сделать результаты открытия публичными, несмотря на нашу неспособность непосредственно известить всех пострадавших, было своего рода призывом к судному дню». Своё нынешнее открытие исследователи сравнивают с памятным многим открытием 2008 года, когда вдруг выяснилось, что сотни тысяч, а быть может, и миллионы криптографических ключей, сгенерированных в системах, работающих под Debian Linux, оказались столь предсказуемы, что атакующая сторона могла их вычислять максимум за несколько часов. Отбирая ключи для последнего исследования, учёные для чистоты эксперимента заранее исключали те, что подпадали под уже скомпрометированную ранее «категорию Debian». Но и при таком подходе пока что осталось совершенно неясным, что именно является причиной для появления больших кластеров ключей, имеющих в себе одинаковые множители. Исследователи пытались выявить какие-либо схожести среди уязвимых ключей в надежде понять причину дефектной работы алгоритмов в генераторах случайных чисел, вырабатывающих криптоключи, но не преуспели. «Единственное наше заключение здесь сводится к тому, что для всех этих проблем, похоже, имеется не единственная причина, — говорит Хьюз. — А это соответственно привело нас к заключению, что до тех пор, пока у вас нет абсолютного доверия к работе вашего генератора случайных чисел, RSA не есть хороший выбор для криптоалгоритма». По мнению криптографов, другие алгоритмы криптографии с открытым ключом, такие, как схема Диффи-Хеллмана и DSA, оказываются не столь фатально уязвимы для компрометации, как RSA. Дело в том, что в альтернативных схемах появление дублей у множителей модуля делает владельца ключа уязвимым только для того человека, с которым непосредственно устанавливается шифрованная связь: «Если с вашим ключом случается коллизия, то вы влияете только лишь на одного другого человека. Вы можете навредить ему, а он может навредить вам, однако вы не можете сделать этот ущерб публичным, как в RSA, где пострадавшим оказывается каждый с таким же фактором-множителем в модуле». Именно по этой причине, собственно, авторы работы и решили дать своей статье несколько необычное название — «Ron was wrong, Whit is right» («Рон был неправ, а прав оказывается Уит»), имея в виду первооткрывателей самых первых криптосхем с открытым ключом, Рональда Райвеста (RSA) и Уитфилда Диффи (Diffie-Hellmann). В качестве эпилога к этой занятной, но невесёлой истории можно привести такие слова из заключительной части исследовательской работы:
id="own_4"> Дмитрий Вибе: Я б в астрономы пошёл Дмитрий Вибе Опубликовано 02 марта 2012 года У астрономии очень красивый фасад. На безупречно чёрном фоне сверкающими брильянтиками выложены фигуры созвездий. Пёстрой мозаикой развешаны по фронтону фотографии, и на каждой — разноцветное космическое чудо. От названий веет тайной и вековой мудростью: планетарная туманность, звёздное скопление, сталкивающиеся галактики, Конская Голова, Никс Олимпика, квазар Лист Клевера… Гигантским усилием воли пытаешься (безуспешно) втиснуть в голову мысль о том, что каждое пятнышко на снимке (а от них рябит в глазах!) — звезда, может быть, подобная Солнцу, а может быть, в тысячи раз более яркая. Что тёмное пятно на фотографии — облако пыли размером в десяток раз больше, чем расстояние от Солнца до Альфы Центавра. Что мы любуемся звёздами, многих из которых уже нет. Тысяча парсеков, сто миллионов градусов, десять миллиардов лет... Помните старый фильм «Весна»? Чтобы подчеркнуть учёность героини, сценаристы вложили в её уста именно внушительное числительное: «Масса Солнца — два октиллиона тонн!» Неподготовленному человеку оценить эту нескончаемую вереницу нулей невозможно. Но есть, по слухам, такие люди, которые прекрасно слышат, как звезда с звездою говорит. Для них палитра фотографий Далёкого Космоса понятна и объяснима. Они знают, как называются созвездья, днём спят, ночи проводят у телескопов и читают небо, как книгу. При этом получают за это интереснейшее занятие зарплату! Так сказать, делают за деньги то, что астрономы-любители делают по любви. На первом курсе я ещё с несколькими энтузиастами всё-таки уговорил руководство, чтобы нам дали сделать на обсерватории что-то научное. Нас привели-таки на телескоп… и мы полночи колдовали с перфолентой, чтобы заставить машинку «Консул» напечатать какие-то таблицы, без малейшего намёка собственно на наблюдения! (Ещё полночи играли в танковый бой на ЭВМ «Наири-К», но сейчас не об этом.) Потому что, как выяснилось, одного энтузиазма недостаточно, чтобы выполнять какие-то астрономически осмысленные действия! Теперь я — настоящий астроном, пробу ставить некуда. Сплю ночью, работаю днём, как все добропорядочные граждане. Сколько я найду на небе созвездий? Десятка два, не больше (это из восьмидесяти восьми). Примерно столько же знаю звёзд. Приобрёл я эти познания в свободное от работы время; для моей профессии они не нужны. Рискну предположить, что многие мои коллеги не знают и этого, особенно теоретики. При этом человек с полным правом именуется астрономом: ведь он изучает звёзды! Ну и что, что он никогда не видел их своими глазами? Астроном-теоретик должен знать физику, математику, английский язык. Названия созвездий ему в работе не пригодятся; к телескопу он может за всю свою карьеру так никогда и не подойти. На теоретиках, конечно, свет клином не сошёлся. Есть ещё и счастливая когорта наблюдателей! У них больше шансов попасть на телескоп, но и эти шансы стремительно сокращаются. Понятно, что современным телескопом вручную управлять невозможно. Как только вы наладили компьютерное управление телескопом, вы вольны поставить управляющий компьютер в километре от инструмента или в тысяче километров от него. И наблюдатель из романтика, проводящего ночи в обнимку с объективами и окулярами, превращается в человека перед монитором, который по внешним признакам работы не отличается от бухгалтера или продавца билетов в кинотеатре. Конечно, ему без определённых знаний о небе уже не обойтись, например чтобы не пытаться наблюдать Полярную звезду в Южной Африке. Но зато у него прекрасно получится успешно проводить наблюдения без малейшего представления о физической сущности наблюдаемых явлений. В целом можно сказать, что нет такой профессии — «астроном». Урания объединяет под своим крылом очень разные занятия, среди которых есть место и для ИТ, и для возни с «железом», и для физики, и для математики... Вот только для любования звёздным небом места почти не остаётся, а реальные снимки космических объектов, с которыми приходится иметь дело, очень мало напоминают цветастые изображения из пресс-релизов и популярных книг. Конечно, астрономия в этом отношении не уникальна. Точно так же нет строго определённой профессии врача, физика, айтишника... Один астроном может совершенно не понимать, чем занимается другой астроном, но точно так же могут не понимать друг друга и два биолога. Отличие астрономии в том, с чего я начал: в наличии манящего разукрашенного фасада, на который, как мотыльки, слетаются очарованные души. Вот их я и хочу предупредить: прежде чем решиться посвятить свою жизнь астрономии, разберитесь с тем, какой смысл вы вкладываете в эти слова. Важно помнить, что в астрономию, как ни в какую другую науку, огромный вклад внесли любители. Однако и в этом случае требуется высокая квалификация, которая вырабатывается многолетним кропотливым трудом. Поэтому я теряюсь, когда (нечасто, но бывает) звонят люди и говорят: «Здравствуйте, мы любим астрономию, хотим помочь вам в ваших исследованиях». Да я для студента-астронома третьего курса не всегда могу задачу подобрать! Интересно, у хирургов такое бывает? «Здравствуйте, я люблю медицину и хочу помогать вам на операциях»... Я не хочу сказать, что работа астронома невыносимо скучна. Она классная! Но её драйв далеко не всегда состоит в том, чтобы просто проводить ночи под звёздным небом. Я написал выше, что к телескопу не подходит, например, теоретик. Но он и не хочет! Физическая интуиция позволяет ему видеть такое, чего не покажет (пока) даже самое большое зеркало. Но если вы планируете карьеру астронома, на всякий случай помните: может получиться так, что телескоп впервые попадёт к вам в руки лет через двадцать, когда вы наконец-то обзаведётесь клочком земли, на который привезёте треногу с любительской трубой. Конечно, она будет без камеры, конечно, она будет небольшая (на большую откуда деньги?), но обязательно с функцией автоматического наведения. Потому что самостоятельно вы сможете навестись разве что на Луну, да и то не с первого раза... P.S. Для соблюдения ритма предлагаю в заголовке колонки произносить слово «астрономы» с ударением на втором слоге. Среди коллег нет единого мнения по поводу того, как следует называть нашу профессию — "астроном" или "астроном". Для определённости сторонникам первого варианта предлагается считать себя франкофилами, сторонникам второго — англофилами! > Голубятня-Онлайн id="sgolub_0">Голубятня: Чудо Compreno Сергей Голубицкий Опубликовано 28 февраля 2012 года Больше всего на свете мне хочется выделить тему сегодняшнего рассказа из потока рядовых событий IT, которыми заполняется информационное пространство моей колонки. Новые гаджеты — это замечательно. Новый удачный софт -бальзам на истерзанную душу пользователя. Проект Compreno, над которым компания ABBYY корпит уже 15 лет и выводит, дай бог, в этом году на стадию готового к потреблению продукта — это не новое, и тем более — не очередное событие. Compreno — это полноценная, не имеющая аналогов в истории технологическая революция. Масштаб этой революции, значение ее для людей (именно для всех людей, а не только для любителей компьютеров) сопоставимы разве что с изобретением World Wide Web или электронной почты. Никак не меньше. Для наглядности можно перевести эту революцию в понятные материально-купюрные реалии: если ABBYY спокойно, без суеты коммерциализирует Compreno хотя бы в десятой части возможных ее практических применений, а затем выйдет на фондовый рынок, капитализация компании затмит всех кумиров сегодняшнего дня — от Apple, грамотно и стильно эксплуатирующего весьма и весьма посредственные в технологическом отношении решения, до Google, умудряющегося заводить в тупик охапками большую часть собственных перспективных начинаний. Впрочем, довольно авансов и эмоций (хотя завсегдатаев Голубятен ни тем, ни другим давно не удивишь O — пора представить Compreno во всем его величии. Начну с лапидарного компендиума: Compreno — это технология перевода любого человеческого языка на универсальный язык понятий. Соответственно, Compreno включает в себя и сам этот универсальный язык понятий, который ABBYY 15 лет (тайком O разрабатывала в своих исследовательских лабораториях. Результат ошеломляет: Универсальная Семантическая Иерархия (УСИ) — ядро языка понятий — насчитывает сегодня 60 тысяч элементов в универсальном разделе когнитивной модели, 80 тысяч — в русском разделе, и 90 тысяч — в английском! Ничего даже отдаленного в мире не существует. Перспективы, которые открывает Compreno, безбрежны и разнообразны: - компьютеризированный перевод текста с любого языка на любой на качественном уровне, несопоставимым со всеми распространенными сегодня системами перевода; - полноценный интеллектуальный поиск без специализированного синтаксиса запросов (Поиск по смыслу, извлечение фактов и связей между объектами поиска/мониторинга; мониторинг компаний и персоналий и построение аналитических отчетов на основе параметров разного типа и др.); системы искусственного интеллекта самых разнообразных профилей и применений; - автоматическое распознавание речи; - классификация документов и поиск похожих документов по смыслу; - анализ тональности в мониторинге; - реферирование и аннотирование (написание краткого содержания длинных документов) и это только начало. За пару дней до своей индийской зимовки я встретился с Татьяной Даниэлян, заместителем директора по лингвистическим технологиям компании ABBYY, и Сергеем Андреевым, генеральным директором и президентом группы компаний ABBYY и на протяжении полных двух часов сидел, широко разинув рот и охая от восторга по мере того, как в мое сознание вливались подробности революционного проекта, подкрепленные полноценной демонстрацией действующего прототипа движков машинного перевода и системы интеллектуального поиска. Все то время, что Сергей и Татьяна, сами едва сдерживая восторг от собственных достижений, стягивали завесу тайны с Compreno, меня не покидало чувство того, что я участвую в каком-то акте добровольного промышленного шпионажа. Согласитесь, масштаб проекта ошеломляет: 15 лет интенсивной работы сотен людей, 50 миллионов долларов собственных инвестиций, совсем недавно усиленных сколковским грантом в 475 миллионов рублей. Вся компьютерная мощь головного офиса ABBYY (а он, поверьте на слово, ошеломляет: 6 этажей 7-этажногоогромного П-образного здания) в любую свободную минуту задействована для просчетов, необходимых для отладки и совершенствования Compreno, в первую очередь УСИ. Впрочем, шпионаж — это лишь в моей голове, поскольку, разумеется, беседа наша состоялась в момент, когда Abbyy вышла на финишную прямую и была готова раскрыть миру свои карты. Подробности Compreno я донесу читателям со слов Сергея Андреева и Татьяны Даниэлян — не потому, что не доверяю собственным суждениям, а потому что рассказ у обоих получился гладким и содержательным, зачем же плодить сущности? Начало разработки Compreno пришлось на 90е годы, когда в арсенале ABBYY (в те годы — еще BIT Software) уже числилось два ледокола: словари Lingvo и программа для распознавания текста FineReader. Продукты продавались по всему миру, были хитами и приносили стабильную прибыль — манна небесная для романтических проектов вроде Compreno, стресс которых не пережил бы ни один сторонний инвестор (вкладывать миллионы долларов в нечто совершенно революционное да к тому же и с неизвестными перспективами? а вдруг ничего не получится? нет уж увольте!). ABBYY обошлась без чужих денег и это спасло Compreno, позволив довести до победного конца проект со столь колоссальными материальными и людскими затратами. Успех обеспечил и правильный изначальный выбор направления для разработки системы автоматического перевода. В 90-е в мире правила одна королева — Rule-Based Translation Model, классическая модель перевода, основанная на ограниченном наборе готовых правил для некоторой пары языков. Одна из проблем RBTM — в накоплении все новых и новых правил, которые в какой-то момент просто начинают конфликтовать между собой. Анализируя предложение, мы можем применить разные комплекты правил, при этом машине неведомы приоритеты. Перевод, основанный на RBTM, как правило, не озабочен полным синтаксическим анализом: вместо него предложение делится на фреймы, на которые затем интерполируют существующие в системе правила для получения перевода. RBMT системы не учитывают семантику. В начале XXI века усилиями Google мир подсел на иглу нового алгоритма перевода — так называемой статистической модели. Основа СМ — наличие обширной базы разнонаправленных переводов. Мы задаем статистическому движку предложение для перевода, он ищет в базе данных как в словаре варианты уже существующих переводов аналогичного текста и после незначительных изменений выдает вполне приличный результат. Изменения не самые существенные. Предположим нам нужно перевести предложение «в комнате стоит красный стул», а в статистической базе уже есть переведенная фраза «в комнате стоит зеленый стол» — решение элементарно: берется уже существующий шаблон перевода и новые слова просто заменяются по словарю. Поскольку в СМ используются уже готовые человеческие переводы заведомо высокого качества, то на выходе получается весьма недурственный результат, ибо для осуществления перевода не нужно погружаться в синтаксис, специфику фразеологии конкретного языка и проч. Все замечательно, однако, лишь до тех пор, пока дело не касается переводов в направлениях с так называемым низким покрытием (скажем, каким-нибудь, румынско-русским или тайско-венгерским). Где брать аналоги? По словам Сергея Андреева опасность подстерегает также при уходе в предметные области на массовых направлениях, потому что параллельных текстов становится сильно меньше, чем в бытовой и разговорной тематике. Сочетание ухода в предметную область и не самого массового направления перевода приводит к слабым результатам. Скажем, IT. Казалось бы, какие сложности могут возникнуть у машинного перевода с текстом на тему информационных технологий? В самом деле — никаких, если мы занимаемся русско-английским переводом. Зато они тут же возникнут на русско-французской ниве! Статистическая база в этом направлении чрезвычайно скудная и лакуны возникают на каждом шагу. Выход в рамках СМ для подобных ситуаций найден лишь паллиативный: работая с языками / темами низкого покрытия в качестве посредника используется английский язык. То есть сперва делается перевод с русского на английский, а затем уже с английского на, скажем, румынский, или тайский. В результате получается очень заметное снижение качества перевода. Самое печальное, что проблема с плотностью покрытия в рамках СМ никак не решается принципиально. Единственный выход: нанять сотни тысяч переводчиков и заставить их заполнять лакуны по всем направлениям с низким статистическим покрытием. Как вы понимаете, никто это делать не сможет и не будет. Помимо сложностей с низкой плотностью переводов по направлениям, выпадающим из узкого мейнстрима, у СМ еще множество мелких изъянов. Например, статистическая модель совершенно убого справляется с переводами имен собственных. Многие помнят о переводе Ющенко, как Януковича, а России как Канады. Отрицание (частичка «не») — это очень сложное препятствие. Частичку «не» можно правильно позиционировать в результате лингвистического анализа текста, а СМ таковым не занимается. В результате предложения, содержащие отрицание, часто переводятся движками на статистической модели с точностью до наоборот. Как бы там ни было, ABBYY изначально отказалась от Rule Based Translation Model и замахнулась на систему компьютерного перевода нового поколения. Надо сказать, что придумывать особо ничего не требовалось. Универсальный язык понятий существует в структурной лингвистике в виде давней и несбыточной мечты еще со времен Людвига Витгенштейна. Даже Наум Хомский в своих ранних трудах лишь углублял существующую утопию. Проект Compreno исходил из трех основополагающих посылок: - использование качественного и бескомпромиссного синтаксического анализа. - создание универсальной когнитивной модели языка, возможность которой определяется аксиомой о том, что люди, хоть и живут в разных условиях и говорят на разных языках, однако в массе своей мыслят одинаково. Формы выражения мысли разные, а вот понятийный аппарат совпадает. - автоматизированное корпусное дообучение — лингвистические описания верифицируются и дополняются на основании статистической обработки корпусных данных. Исходя из этих посылок была сформулирована идея Универсальной Семантической Иерархии (УСИ), способной описывать явления от общего к частному. На составление этой иерархии у ABBYY и ушло 15 лет. Получилось то, что вы уже знаете: только на сегодняшний день 70 тысяч понятий в универсальной части когнитивной модели, более 80 тысяч — в русской, более 90 — в английской. Алгоритм машинного перевода, основанного на УСИ, выглядит следующим образом: - Лексический анализ текста (выделение слов, знаков препинания, цифр и прочих текстовых единиц); - Морфологический анализ (определение грамматических характеристик лексем); - Синтаксический анализ (установление структуры предложения); - Семантический анализ (выявление выражаемого значения в системе языка); - Синтез из универсальной семантической структуры предложения на выходном языке. В результате подбор слов для перевода осуществляется не напрямую из первого языка, а из понятийного набора, который, условно говоря, «висит» на той же ветке универсального семантического дерева, но только уже со стороны второго языка. Поскольку модель УСИ сквозная, нижестоящие элементы системы по иерархии наследуют признаки вышестоящих элементов. Это простое, казалось бы, обстоятельство позволяет добиваться беспрецедентной точности машинного перевода, поскольку каждое слово из переводимого предложения описывается максимальным набором понятийных эквивалентов, причем не только видового, но и родовых качеств на всех уровнях смысловой иерархии. В УСИ предусмотрены взаимосвязи между элементами структуры, относящимися к разным классам, и эти связи также структурированы и формализированы, что позволяет выполнять многоуровневый понятийный анализ текста, также повышающий качество перевода. В процессе создания УСИ разработчикам открылись неожиданные грани использования системы: помимо машинного перевода язык УСИ можно использовать в интеллектуальных смысловых поисках и, возможно, автоматическом распознавании речи на новом качественном уровне, который достигается за счет глубокой интеграции и взаимопроникновения синтаксиса и семантики в модели универсальной семантической иерархии. На альтернативных направлениях возникают, конечно, и свои сложности. Скажем, сегодня самым узким местом для глобального применения семантико-синтаксического анализа в массовых поисковых системах выступают очень высокие требования к компьютерным мощностям, необходимым для индексации информационных массивов на понятийном уровне. Требования эти несоизмеримо выше, чем при существующих формах традиционной индексации. Впрочем, уже сегодня методика семантико-синтаксического анализа может эффективно применяться (и применяется ABBYY — видел полностью функциональный прототип поискового движка собственными глазами) для более целенаправленного и узкого поиска в закрытых корпоративных системах. Мировых аналогов у Compreno сегодня нет, хотя в некоторых университетах и ведутся разработки в аналогичных направления. Однако фора в 15 лет, задействованные огромные человеческие ресурсы и материальные затраты позволяют надеяться, что ABBYY таки сумеет застолбить для себя эксклюзивное место первопроходца. На руку компании играет и то обстоятельство, что последние 10 лет подавляющая масса исследований в мире велась в русле статистической модели машинного перевода. За теоретическим введением в Compreno последовало более чем часовое погружение в демонстрацию работы движка компьютерного перевода, основанного на УСИ. Я сидел в одном из конференц-залов офиса ABBYY и непрестанно протирал глаза, все еще до конца не веря в услышанное и увиденного.
Теперь пользуюсь разрешением и демонстрирую читателям сравнение переводов, выданных Compreno и статистическим переводчиком (каким — гостеприимные хозяева просили не называть, но думаю, не маленькие и сами догадаетесь O Не сомневаюсь, что для любого человека, знающего толк в переводах, это сравнение откроет новую вселенную. Вот работа статистического переводчика (разумеется, предложения подобранны специально «поддых», поскольку бьют в самые слабые места статистической модели перевода).
Это, господа, просто другой космос, другой уровень понимания текста. Это — революция! Смотрел я на это, слушал внимательно и, похоже, начал улавливать тайный смысл (шуточного) мотивационного плаката, висящего в одном из офисных коридоров ABBYY:
|
|
|||
|
Главная | В избранное | Наш E-MAIL | Добавить материал | Нашёл ошибку | Наверх |
||||
|
|
||||